
Lec 01-1: Tensor Manipulation 1
딥러닝 공부 1일차
Vector, Matrix, Tensor 에 대해서
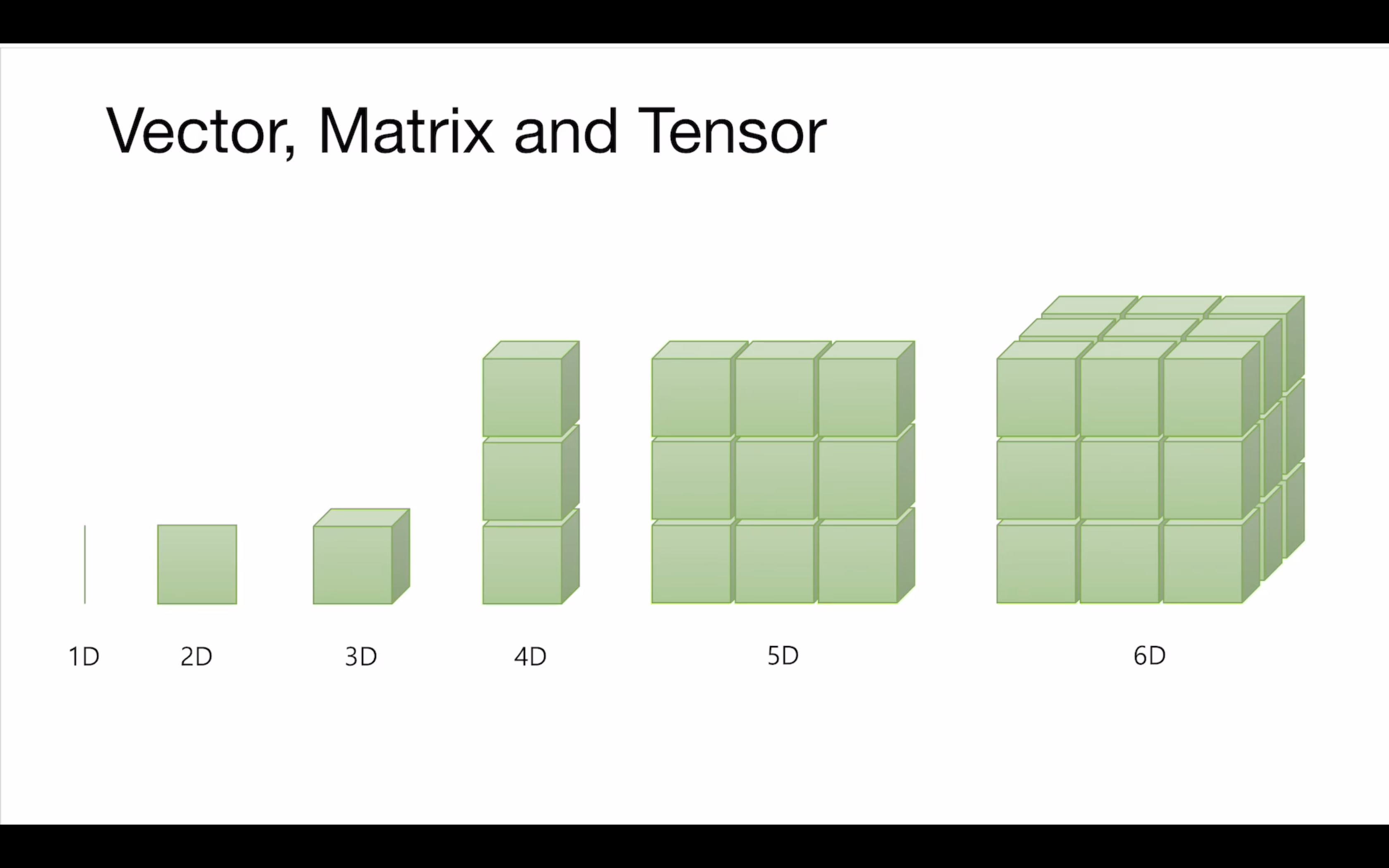
(출처: 부스트코스, 파이토치로 시작하는 딥러닝)
여기서는 우리가 흔히 일상생활에서 쓰이는 3D,4D할 때의 dimension 과는 느낌이 조금 다르다. 한개씩 쌓아올라가는 느낌으로 받아 들이면 좋을 것 같다.
설명의 편의성을 위해서 (ex. 2D,3D…의) D를 이 글에서는 차원이라고 말하겠다.
위 그림과 같이 맨왼쪽의 1D는 벡터라고 한다, 딥러닝에서 벡터는 선형대수적인 방향의 개념까지 내포하는 것 같지는 않는 것 같다. 차차 알아봐야겠다
-
2D는 우리가 흔히 알고있는 matrix, 즉 행렬이다.
-
3D는 행렬에서 뒤쪽으로 추가된 직육면체모양이고 이를 Tensor 라고 부른다.
-
4D는 그러한 텐서가 위쪽방향으로 쌓아올라간 모양이라고 보면 된다.
-
5D는 앞서생긴 4D모양에서 우측으로 쌓아올라가는 모양, 6D는 5D모양에서 뒤쪽으로 쌓아져 올라가는 느낌이다.
기존틀에서 하나씩 쌓아져 올라가는 특징이라 7D, 8D… 도 예측할 수 있을 것 같다.
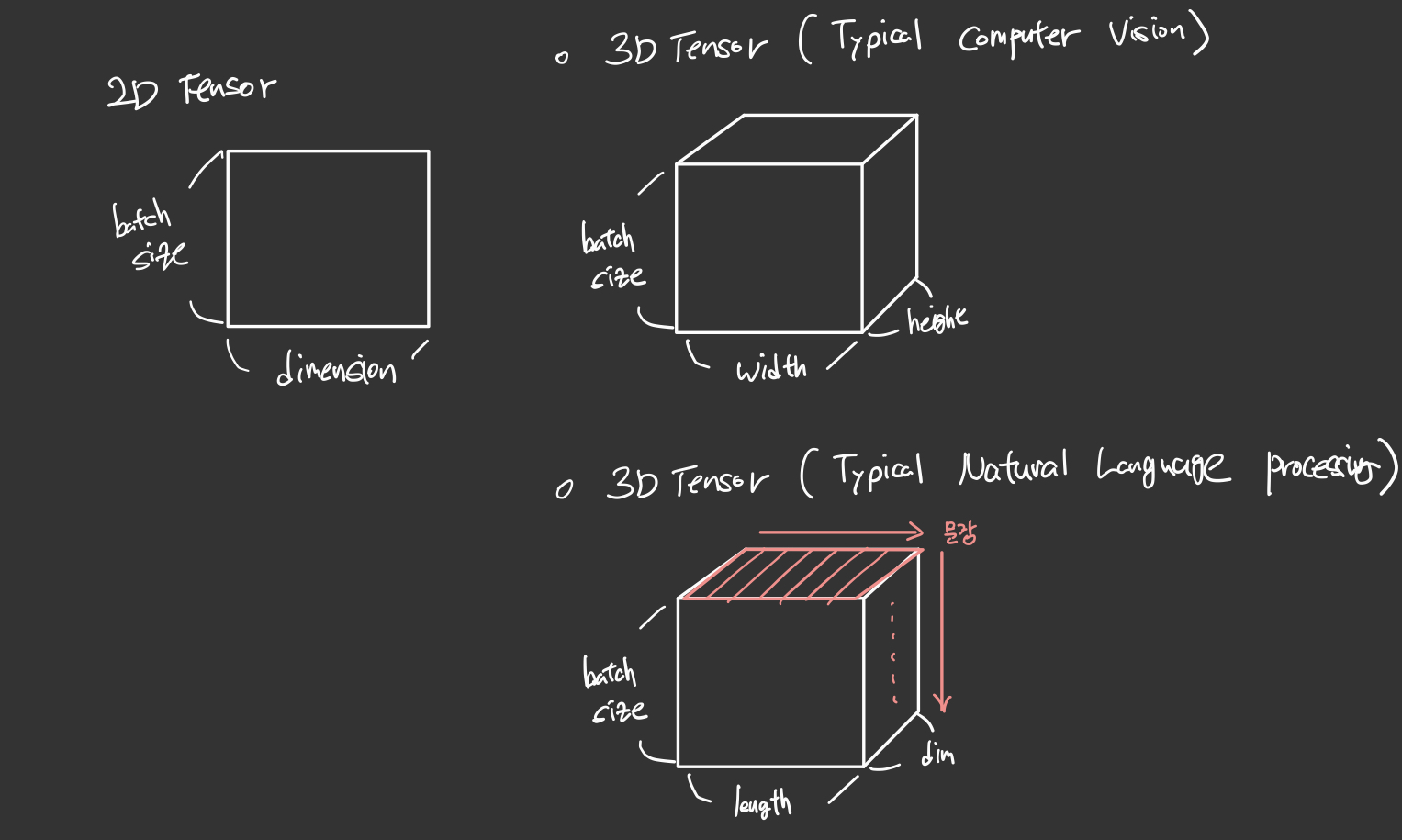
Tip : 차원이 쌓아져 올라가는 순서로 보면 편하다
-
2D 텐서에서는 가로를 dimension 이라하고 세로를 batch size 라고 부른다.
-
3D 텐서 (특히, 컴퓨터비전)에서는 가로(width), 세로(batch size), 높이(height)
흔히 우리가 그동안 살아오면서 보았던 육면체에서 높이는 현재 그림의 dimension에 해당하는데 딥러닝에서는 쌓아올라가는 순서에의해 그림과같이 기존의 상식선으로 세로에 해당하는 부분을 높이라고 하는 것 같다.
-
3D 텐서 (특히, 자연어처리)에서는 기존 2D 텐서에서 가로(dimension), 세로(batch size)가 책장에 책을 꽂듯이 차곡차곡 쌓이는 느낌으로 높이(length)라고 보면 될 것 같다. ㅤㅤㅤㅤ
1D Array with Numpy
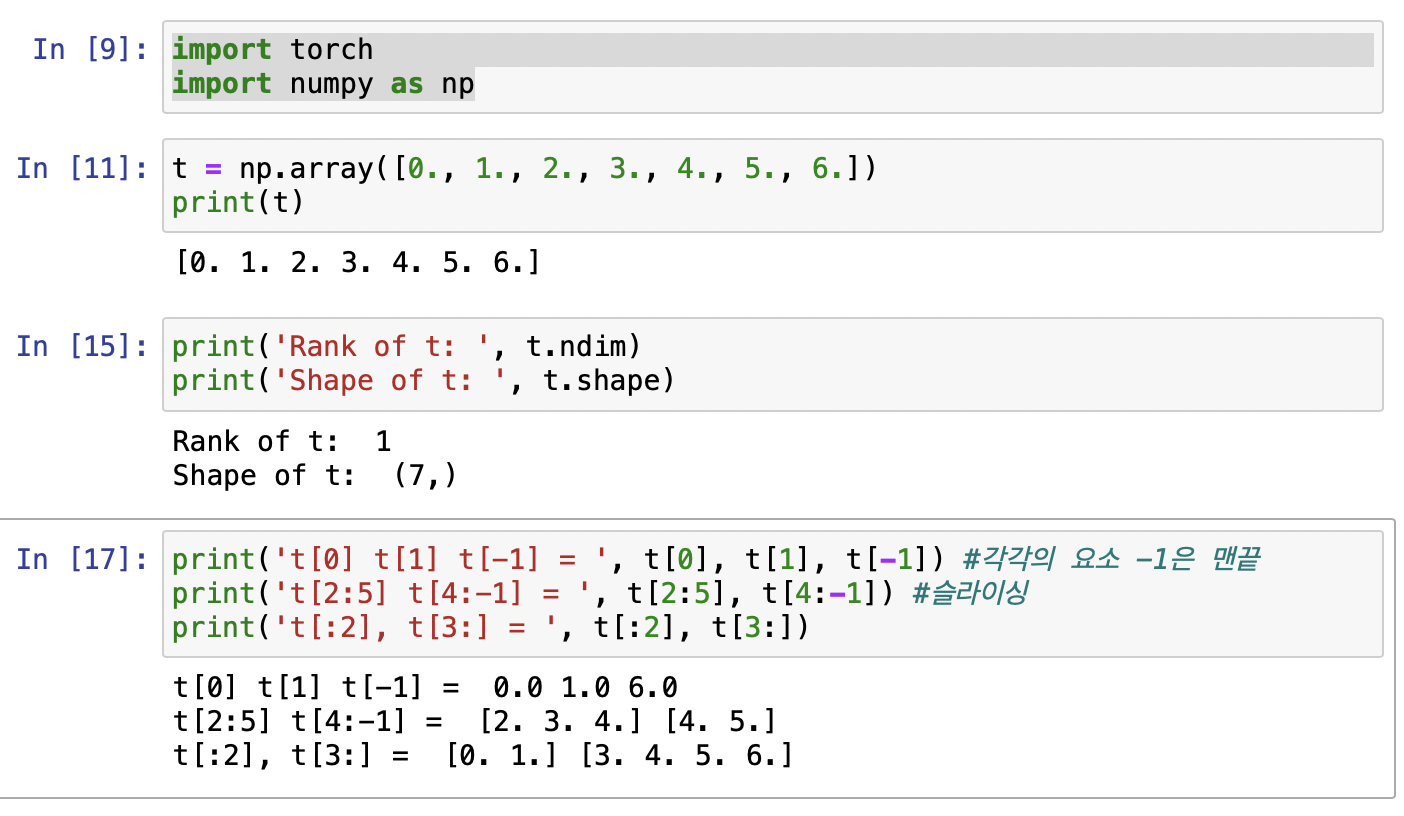
이제 Anaconda 에서 개발환경 구축했던 torch로 설정해주시고 코딩을 해봅시다! ㅤ ㅤ
-
Numpy 란?
Numpy는 다차원 배열을 쉽게 처리하고 효율적으로 사용할 수 있도록지원하는 파이썬의 패키지입니다. NumPy는 데이터 구조 외에도 수치 계산을 위해 효율적으로 구현된 기능을 제공합니다. 데이터 분석을 할때, Pandas와 함께 자주 사용하는 도구로 등장합니다.
한마디로 vector, matrix, tensor 같은 놈들끼리 연산을 쉽게 해주는 놈.
파이썬의 특징으로 배열을 슬라이싱할 수 있다는 점인데 워낙 직관적인 언어라 사진예제만 봐도 이해할 수 있다.
2D Array with Numpy
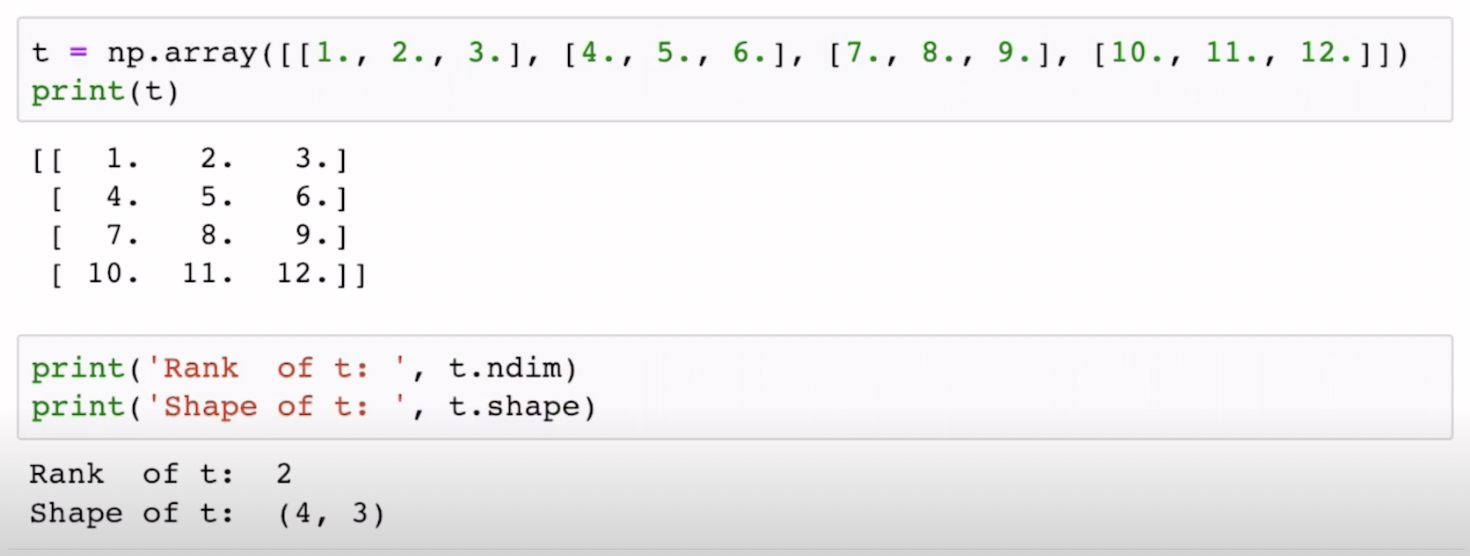
기존 선형대수를 공부해본 사람이라면, 그림과 같은 행렬의 rank가 어떻게 2가 나오지? 라고 생각이 들 수 있지만 여기서 rank는 위에서 설명했던 차원으로 보았을때 2D array기 때문에 rank 값이 2가 나오는 것이다.
shape 모양은 4행 3열.
1D Array with Pytorch
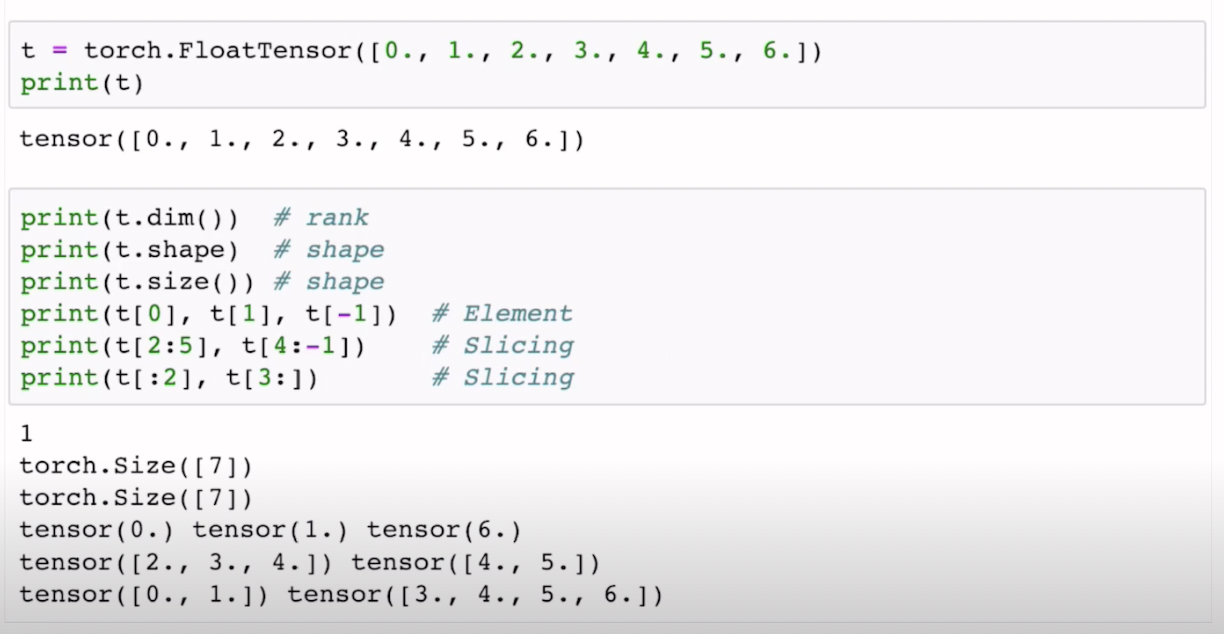
여기서 Python과 Pytorch 차이점이 하나 있다. 바로 기존 C언어에서 처럼 int, float 등 형태를 지정해줘야한다는 것!
2D Array with Pytorch
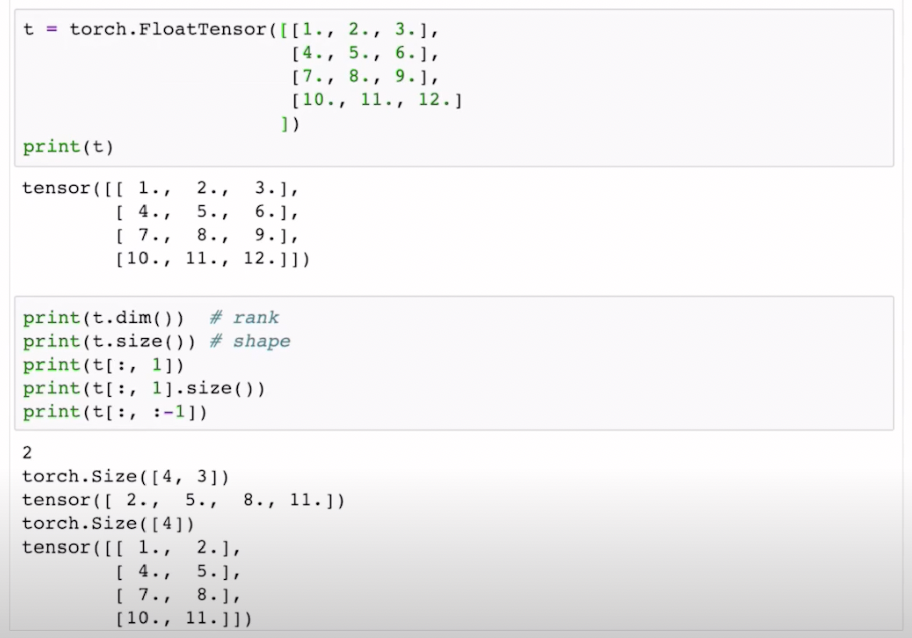
여기서 내가 잘 몰랐던 부분은 slicing 표현법인데 t[:,1] 는 행은 다불러오고 열은 1번째를 불러와라 (0부터 카운트 주의)
또한 t[:, :-1] 은 행은 다 불러오고 마지막에서 첫번째를 제외하고 불러와라 라는 표현법이였다. (-로 세줄때는 1부터 카운트 주의)
BroadCasting
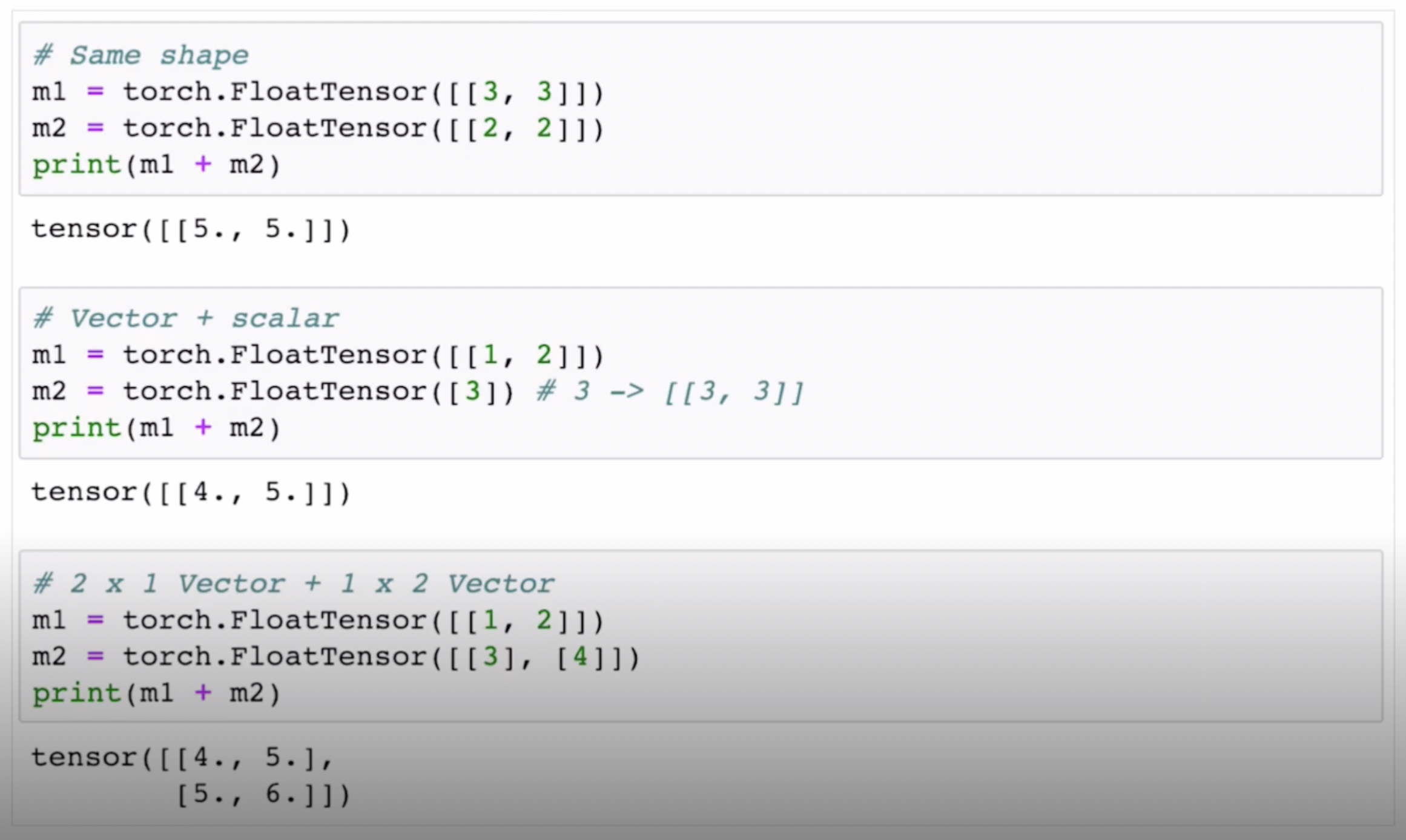
파이썬의 넘파이나 파이토치에서 제공하는 기가막힌 기능중 하나가 바로 브로드캐스팅이다. 행렬이나 벡터연산간에 원래는 그 크기가 서로 맞아야 계산이 가능했지만 (ex. 2by3 X 3by4 = 2by4)
그림처럼 알아서 그 크기를 계산에 필요한만큼 변화시켜서 계산해준다! wow
Multiplication VS Matrix Multiplication
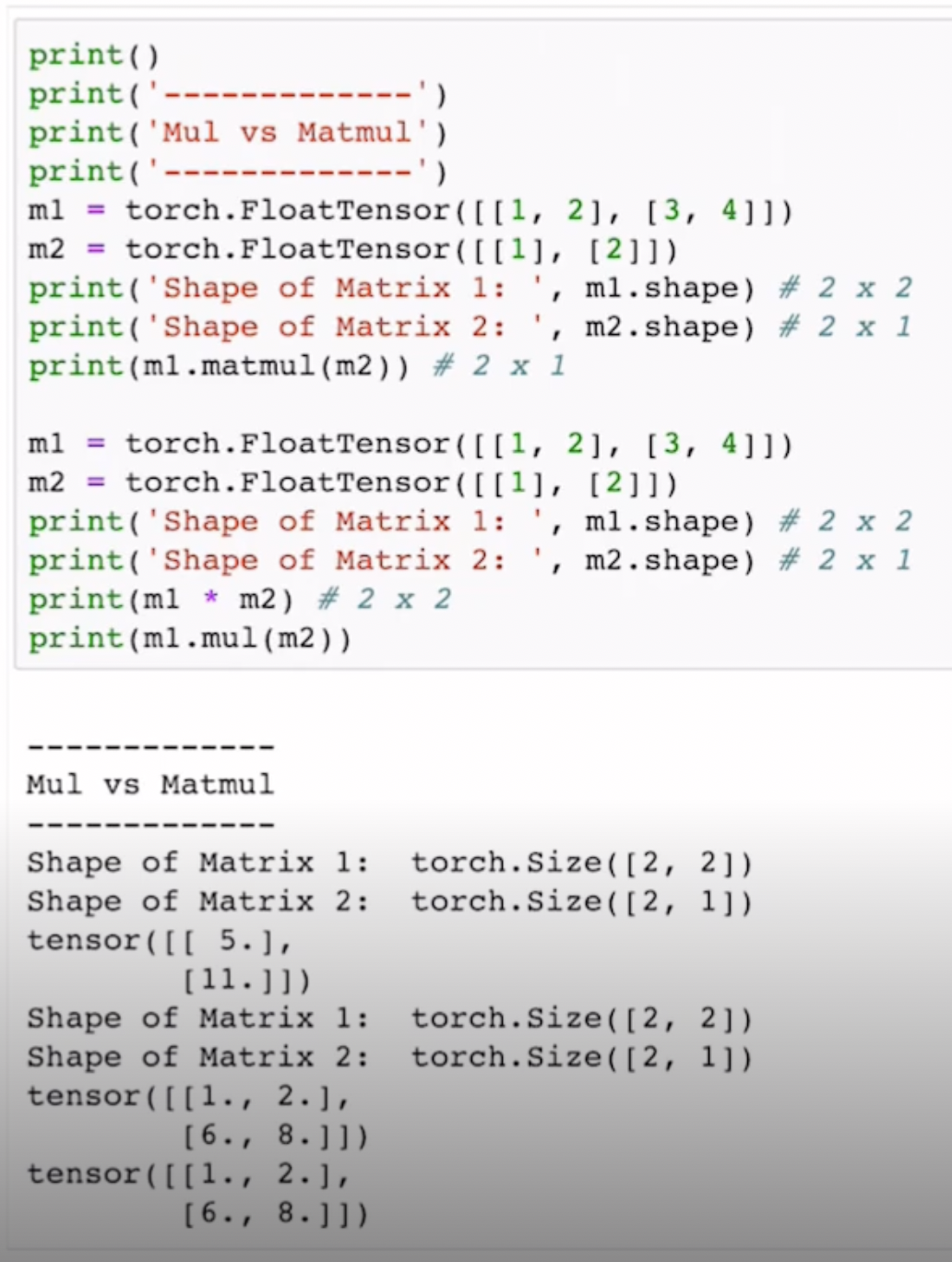
결과값에서 보아 알 수 있듯이, 그냥 곱셈은 요소별 곱(element-wise product)을 계산합니다. 기호는 * 곱연산자를 사용하고 A.mul(B) 와같은 형태로 사용합니다.
반면에 행렬의곱은 선형대수학에서 하는 행렬의 곱셈연산을 말하며 기호로는 @ 을 사용하고 A.matmul(B) 와같은 형태로 사용합니다.
Mean(평균값)
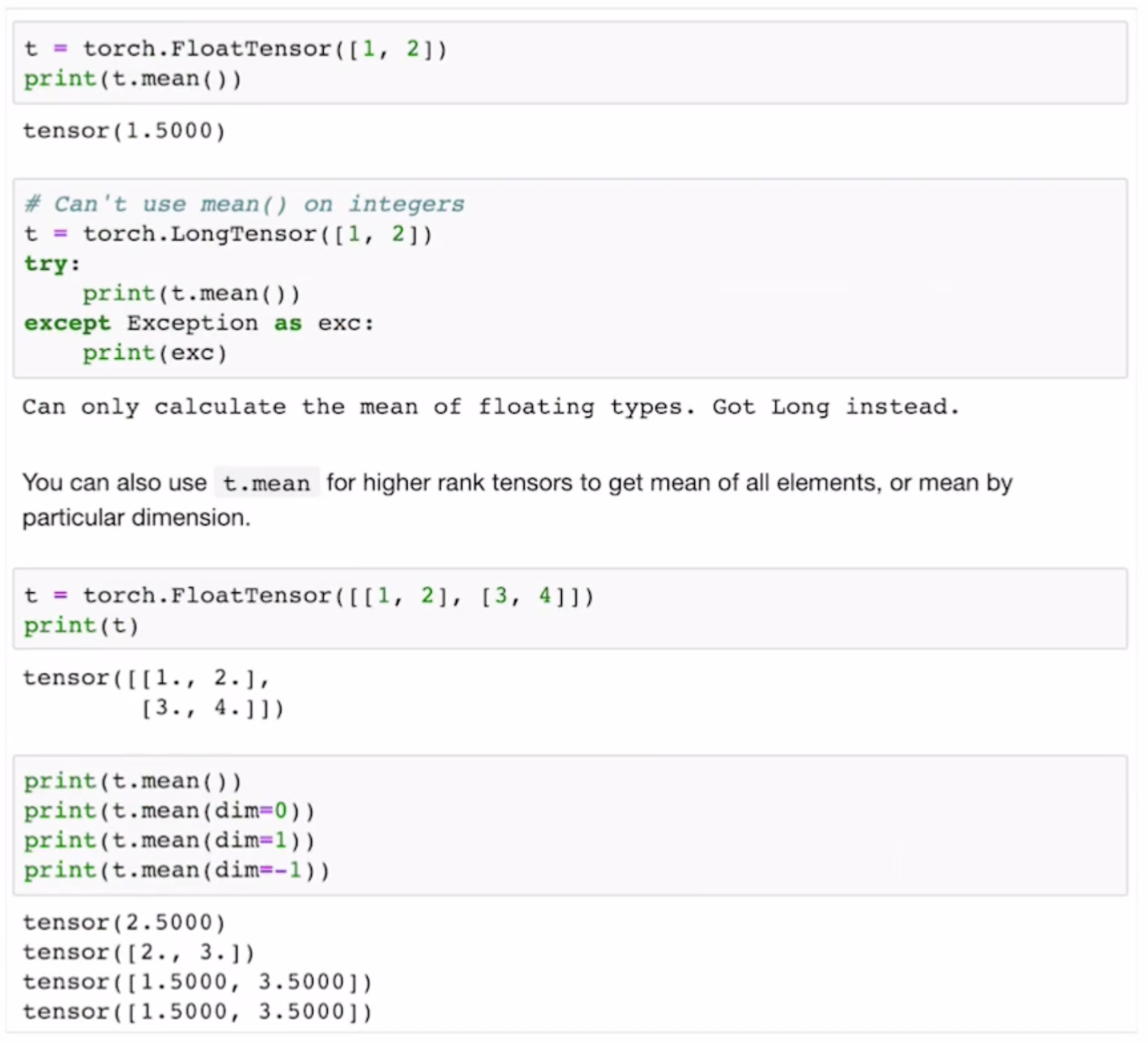
말그대로 각 elements 들의 평균을 구해주는 함수입니다. 평균은 floating 타입에서만 연산이 가능합니다.
print(t.mean()) # 각 elements 들의 합의 평균
print(t.mean(dim=0)) # 행렬의 첫번째 요소인 행을 지우라는 의미
# 1by2 행렬을 만들어라! 그래서 1과3 그리고 2와4의 평균값이 요소가 된다.
print(t.mean(dim=1)) # 행렬의 두번째 요소인 열을 지우라는 의미
# 2by1 행렬을 만들어라! 그래서 1과2 그리고 3과4의 평균값이 요소가 된다.
Sum(합산)

위의 평균값의 원리와 동일하게 계산하나 더하기만 하면 됩니다.
Max & Argmax
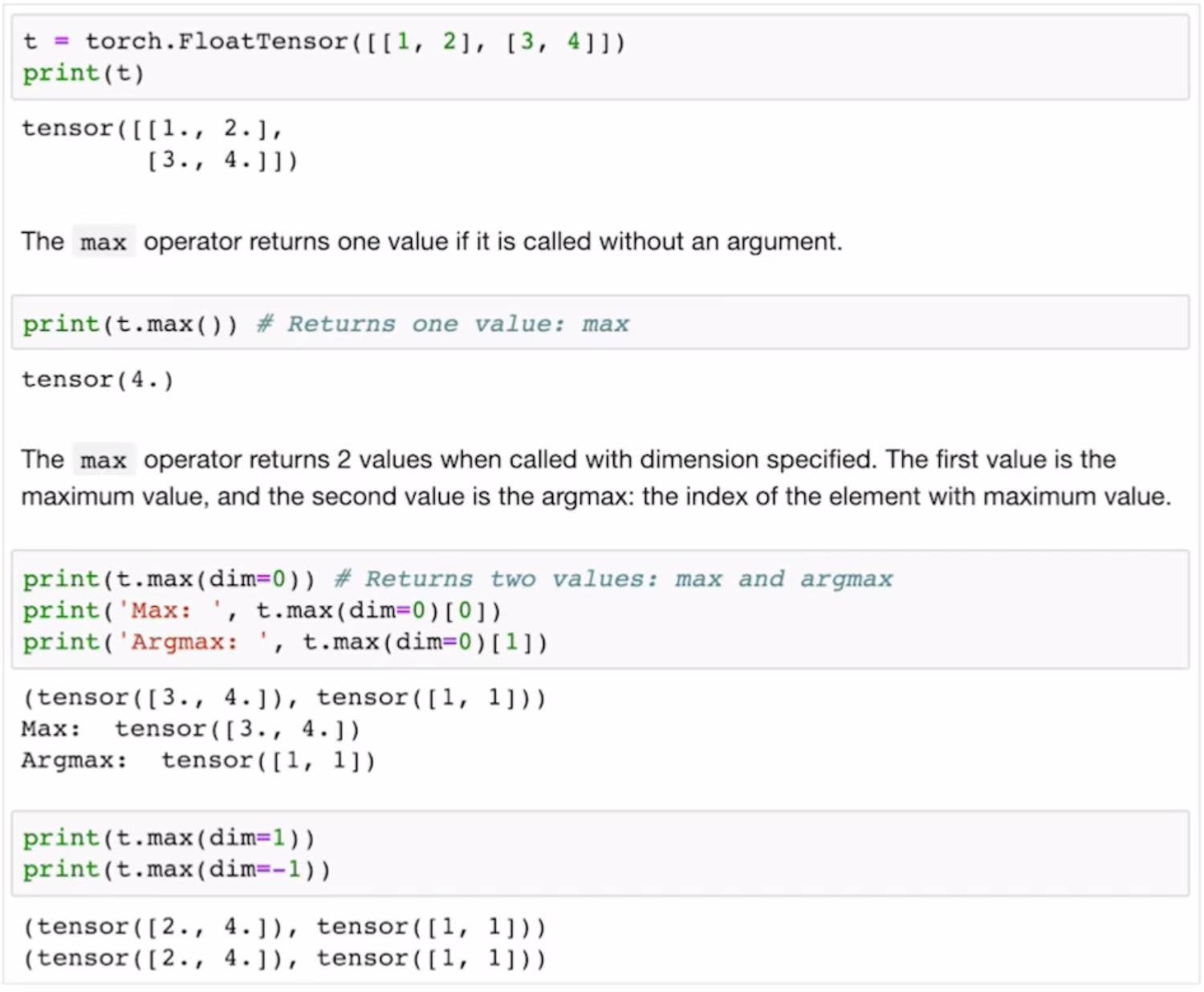
Max는 말그대로 그 matrix 요소중 제일 큰 값을 반환하고, Argmax는 최대값을 가진 인덱스를 반환합니다. 여기서도 마찬가지로 dim을 사용하면 해당차원은 제거하고 연산을 행해주면 되는데요!
ㅤ dim=0이라고하면 첫번째 차원인 행을 지워달라는 의미이므로 1과3 중에 큰값인 3이 2와4 중에 큰값인 4가 나와 (2,4) 텐서가 출력됩니다.
그리고 tensor([1,1])이 반환되는데, max에 dim인자를 주면 argmax도 반환되는 특징 때문입니다.
[[1,2], [3,4]]에서 첫번째 열의 0번째 인덱스가 1, 1번째 인덱스가 3이고. 두번째 열의 0번째 인덱스가 3이고 1번째 인덱스가 4라서 반환이 tensor([1,1])이 나오게 되는 것입니다.
두개의 반환값중 한가지만 받고싶을 때 array값을 불러오듯이 [0] 을하면 최대값이 [1]을 하면 argmax값을 받아올 수 있습니다.
참고문헌 : wikidocs
댓글남기기