
Lec 05: Logistic Regression
딥러닝 공부 6일차
Logistic Regression
일상속의 많은 문제들중에 두개의 선택지중에 정답을 고르는 문제들 같은 경우가 많습니다. 예를들어 계절학기의 Pass or Non_pass 라던지, 받은 메일이 스팸인지 아닌지 이런식으로 이분법적으로 나누는 경우를 Binary Classification(이진 분류) 라고 합니다.
그리고 이러한 이진 분류를 풀기 위한 대표적인 알고리즘이 Logistic Regression 입니다.
이 로지스틱 회귀는 이진 분류의 특성 때문에 Regression(회귀)로 사용하지만 Classification(분류)로도 사용이 가능합니다.
Binary Classification
이번 여름방학 계절학기 학생들의 성적으로 패논패를 부여한다고 해봅시다. 60점 이상이면 패스, 60점 아래면 논패스라고 예를 들어보겠습니다.
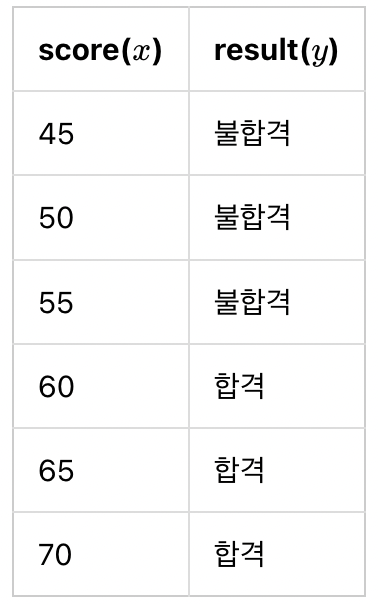
위와 같이 6명의 학생의 점수가 있다고 생각해봅시다. 6명의 학생의 점수중 앞서 말한 것 처럼 패스한 학생을 1 논패스한 학생을 0으로 표햔해보면
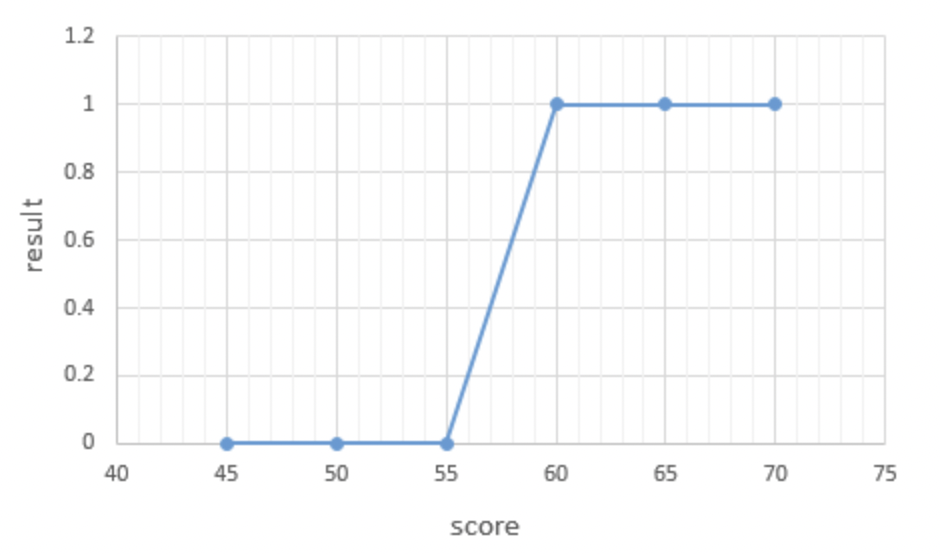
그 동안 배웠던 가설함수인 직선의 형태로는 위 그림과 같은 모양을 표현하기엔 다소 어려움이 있어보입니다.
그래서 우리는 이번에 새로운 함수를 배우게됩니다. 이번 로지스틱 회귀에서의 가설은 $H(x) = Wx + b$ 가 아니라 $H(x) = f(Wx + b)$ 꼴을 사용하게 됩니다.
위의 그림과 같은 함수를 표현하기위한 함수로 시그모이드함수가 있습니다.
시그모이드 함수
시그모이드 함수의 원형은 아래와 같습니다. 이제 x대신에 Wx+b 가 대입되면 됩니다.
\[sigmoid(x) = \frac{1}{1 + e^{-x}}\]시그모이드 함수의 그래프를 그려보면 다음과 같습니다.
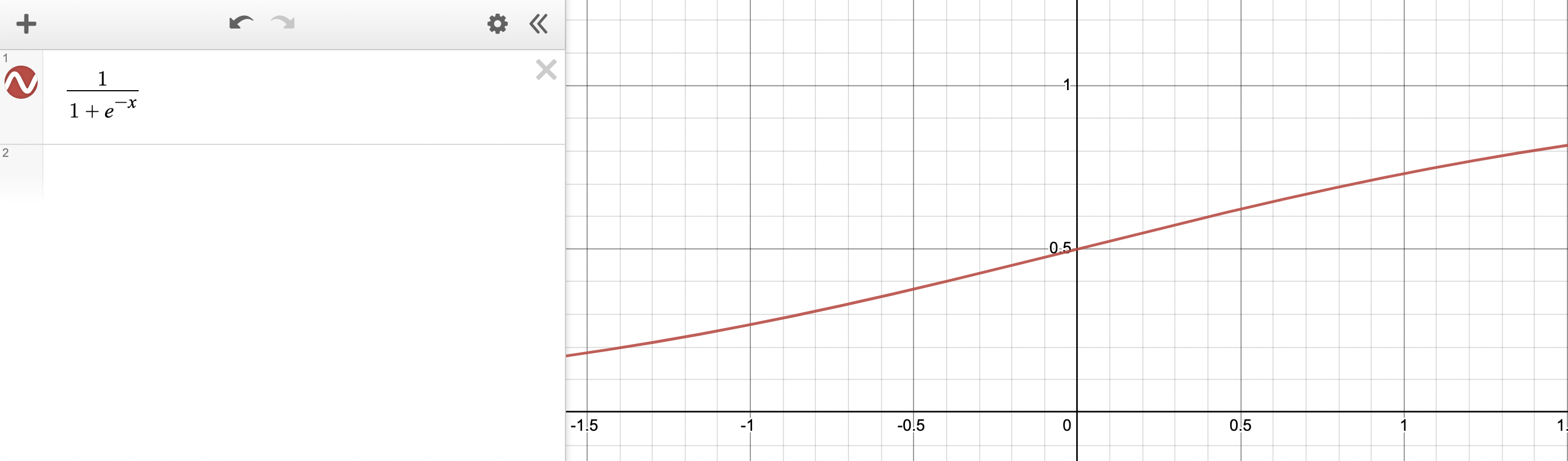
위 그림이 시그모이드 함수입니다. x가 $-\infty$ 로 향하면 0으로 다가가고, 반대로 $\infty$ 로 향하면 1로 다가가는 함수입니다. 추가로 $f(0)=0.5$ 입니다.
\[H(x) = sigmoid(Wx + b) = \frac{1}{1 + e^{-(Wx + b)}} = σ(Wx + b)\]선형회귀에서는 W가 기울기를 b가 y절편을 의미했다면, 시그모이드함수에서 W 와 b는 함수의 모양과 위치의 차이가 변화합니다.
직접 코드를 쳐보면서 함수가 어떻게 변하는지 확인해봅시다.
- 파이썬에서는 그래프를 그릴 수 있는 도구로서 Matplotlib을 사용할 수 있습니다.
- Matplotlib 자세한 사용법 은 여기를 참고해주세요.
%matplotlib inline
import numpy as np # 넘파이 사용
import matplotlib.pyplot as plt # 맷플롯립사용
만약 위의 코드를 주피터 노트북에 실행했더니 오류가 나시는 분들은 matplotlib가 안깔려 있어서 그렇습니다. 그럴 때는 아래 코드를 주피터노트북에서 실행해주세요.
pip install matplotlib
설치가 완료되셨으면 직접 코드를 입력하면서 함수의 변화를 관찰하시면 좋을 것 같습니다.
시그모이드 함수를 불러오려면 다음과 같이 코드를 입력하시면 됩니다.
def sigmoid(x): # 시그모이드 함수 정의
return 1/(1+np.exp(-x))
np.exp라고하면 자연상수를 밑으로 가지는 지수함수가 소환이됩니다 그다음 괄호에 들어오는 수 또는 문자가 지수의 역할을 합니다.
x = np.arange(-5.0, 5.0, 0.1) # x갑인 -5부터 5까지 0.1칸마다 점을찍겠다
# -> 직선은 점들의 집합임을 생각하면 좋을 것 같습니다.
y = sigmoid(x)
plt.plot(x, y, 'g') # 초록색 선으로 그려라라는 의미
plt.plot([0,0],[1.0,0.0], ':') # 가운데 점선 추가
plt.title('Sigmoid Function')
plt.show()
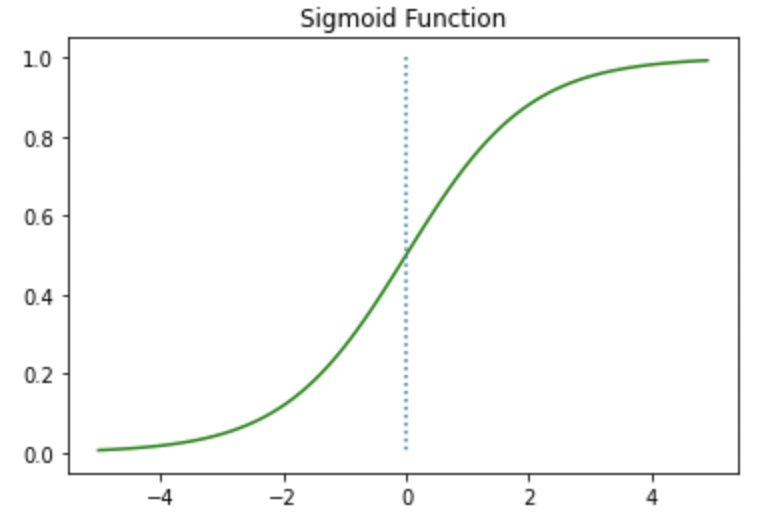
위의 그래프 사진과 동일하죠? 그렇다면 잘 소환한 것입니다.
W 값에 따른 경사도 변화
이제 W값을 변화시켰을 때, 함수가 어떻게 변화하는지 알아보겠습니다.
시그모이드 함수로 가설을 사용할때는 $H(x) = f(Wx + b)$ 라고 앞에서 설명드렸습니다.
하지만 여기서는 W 값에따른 변화만을 관찰하기위해서 $f(Wx)$ 즉, 편향을 제외하고 코드를 입력해보았습니다.
x = np.arange(-5.0, 5.0, 0.1)
y1 = sigmoid(0.5*x) # W=0.5
y2 = sigmoid(x) # W=1
y3 = sigmoid(2*x) # W=2
plt.plot(x, y1, 'r--') # W의 값이 0.5일때, 빨간 점선
plt.plot(x, y2, 'g') # W의 값이 1일때, 초록선
plt.plot(x, y3, 'b--') # W의 값이 2일때, 파랑 점선
plt.plot([0,0],[1.0,0.0], ':') # 가운데 점선 추가
plt.title('Sigmoid Function')
plt.show()
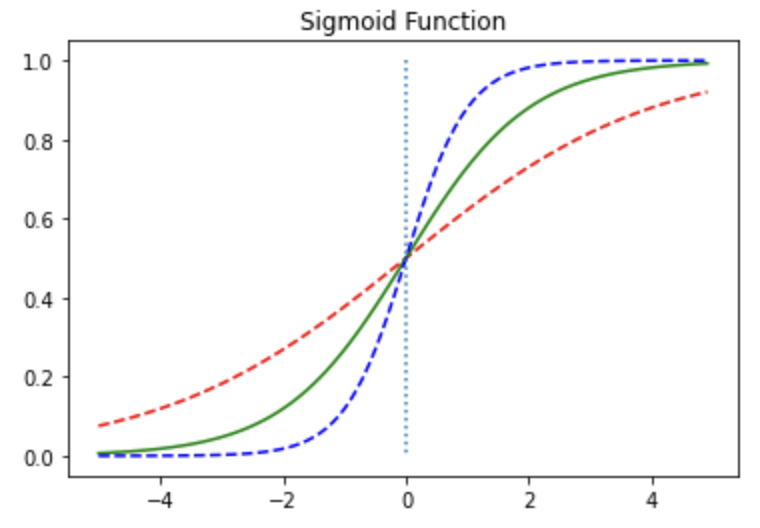
이와같이 가중치 값이 크면 경사가 커지고, 가중치값이 작아지면 경사가 작아지는 것을 확인하실 수 있습니다.
간단히 생각해보면, 극단적으로 시그모이드함수에서 가중치값이 0이라고 생각해보면
\[Sigmoid(x) = \frac{1}{1+e^{0}} = \frac{1}{2}\]즉 $y=0.5$ 인 경사각이 없는 직선이 나온다고 생각해볼 수도 있을 것 같습니다.
b 값에 따른 좌,우 이동
이제 b 값에 따라서 그래프가 어떻게 달라지는지 확인해보겠습니다.
위에서 함수를 설명해드렸으니 감이 오시죠? 이번엔 $f(x+b)$ 꼴로 W를 1로 고정해놓고 편향이 추가된 모습입니다.
지정해야할 색깔이 많을 때는 ‘C~’ 를 이용하면 편할 것 같아요~
x = np.arange(-5.0, 5.0, 0.1)
y1 = sigmoid(x+0.5)
y2 = sigmoid(x+1)
y3 = sigmoid(x+1.5)
y4 = sigmoid(x)
y5 = sigmoid(x-0.5)
y6 = sigmoid(x-1)
y7 = sigmoid(x-1.5)
plt.plot(x, y1, 'C0--') # x + 0.5
plt.plot(x, y2, 'C1--') # x + 1
plt.plot(x, y3, 'C2--') # x + 1.5
plt.plot(x, y4, 'k') #원래 시그모이드함수
plt.plot(x, y5, 'C3--') # x - 0.5
plt.plot(x, y6, 'C4--') # x - 1
plt.plot(x, y7, 'C5--') # x - 1.5
plt.plot([0,0],[1.0,0.0], ':') # 가운데 점선 추가
plt.title('Sigmoid Function')
plt.show()
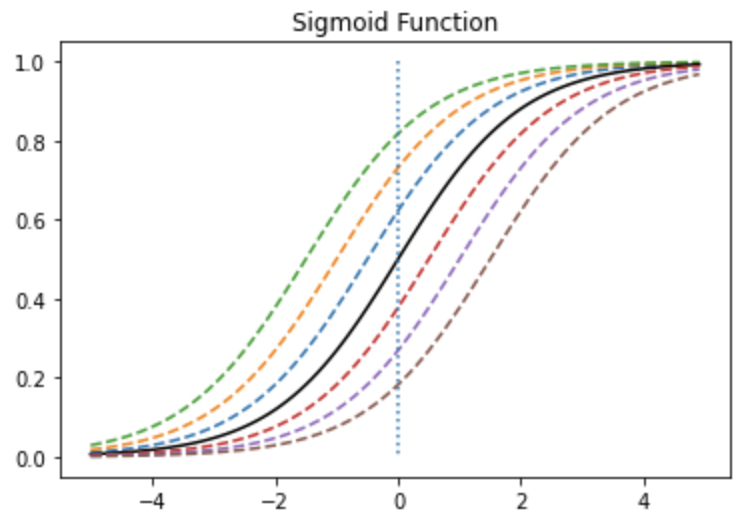
편향이 클수록 함수가 좌측으로 평행이동 되고 있습니다. 또한 편향이 작을수록 우측으로 평행이동 되는 모습입니다.
이차함수의 꼭지점의 평행이동을 생각해보면 이해가 더 빠를 것 같습니다.
Cost Function(비용 함수)
이제 로지스틱 회귀의 가설함수가 $H(x) = sigmoid(Wx + b)$ 인 것은 알았습니다. 이제 이 가설함수로 비용 함수를 설정할건데,
선형 회귀에서 배웠던 MSE 함수로 하면 될까요?
\[cost(W, b) = \frac{1}{n} \sum_{i=1}^{n} \left[y^{(i)} - H(x^{(i)})\right]^2\]기존의 선형회귀에서는 전구간에서 아래로 볼록했기 때문에 최적의 W 와 b를 찾는 과정이 단순 미분을 통해 기울어진 방향으로 어떻게든 이동하게 되었지만 (아래 그림참고)
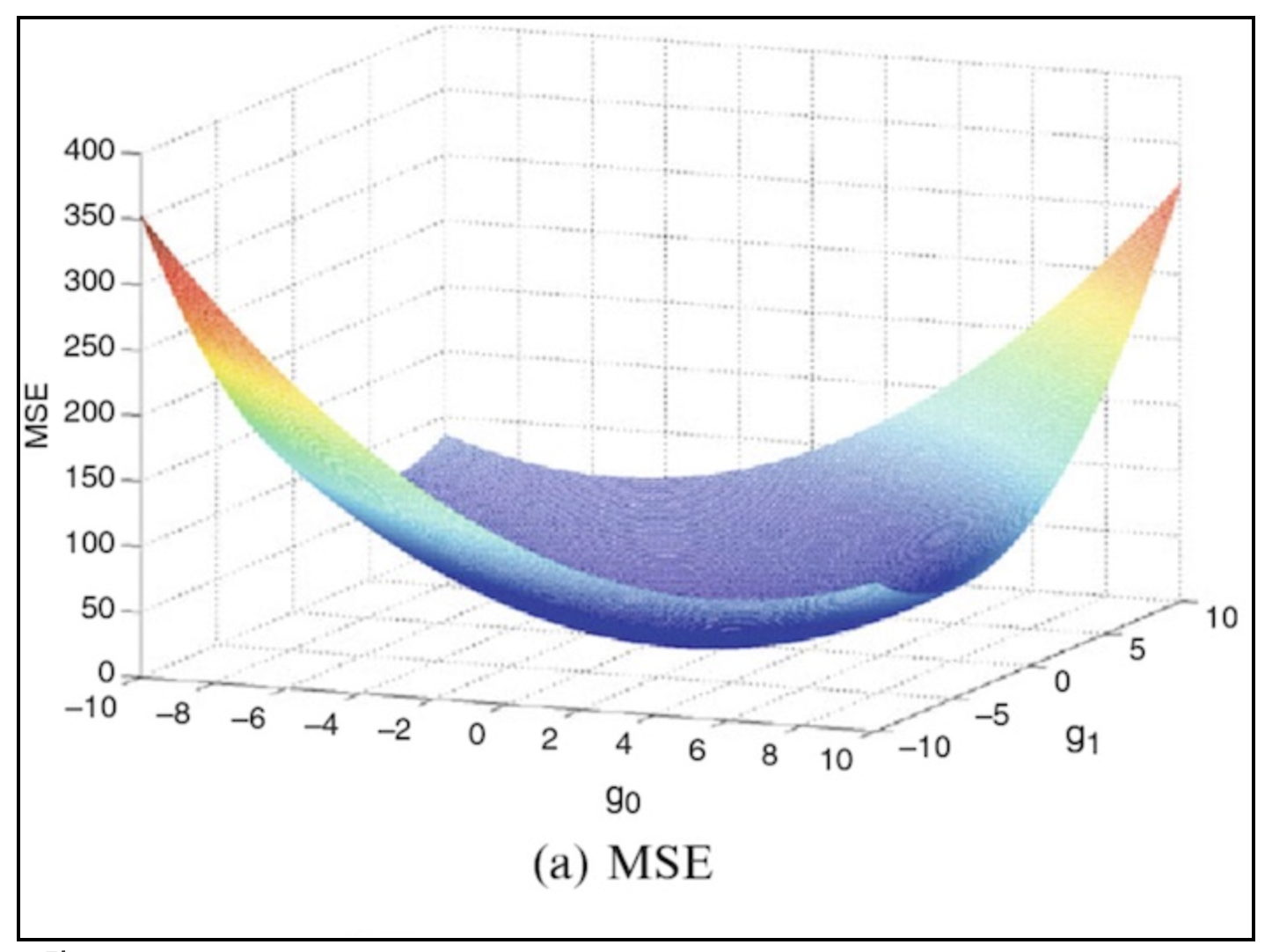
이제는 위의 비용함수 수식에서 가설은 이제 직선이 아니라 시그모이드함수를 대입을하게 됩니다.
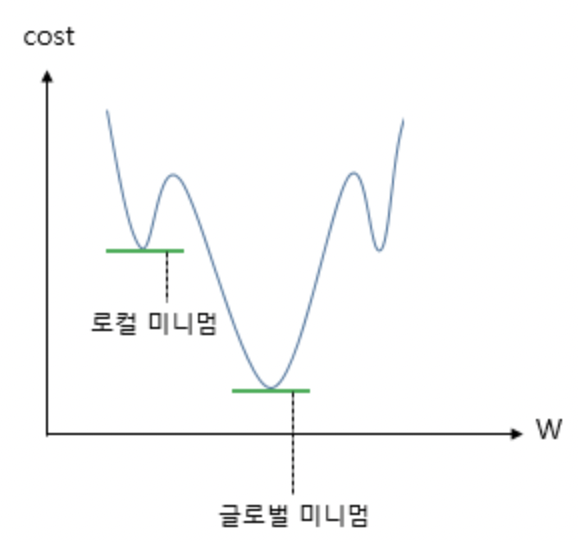
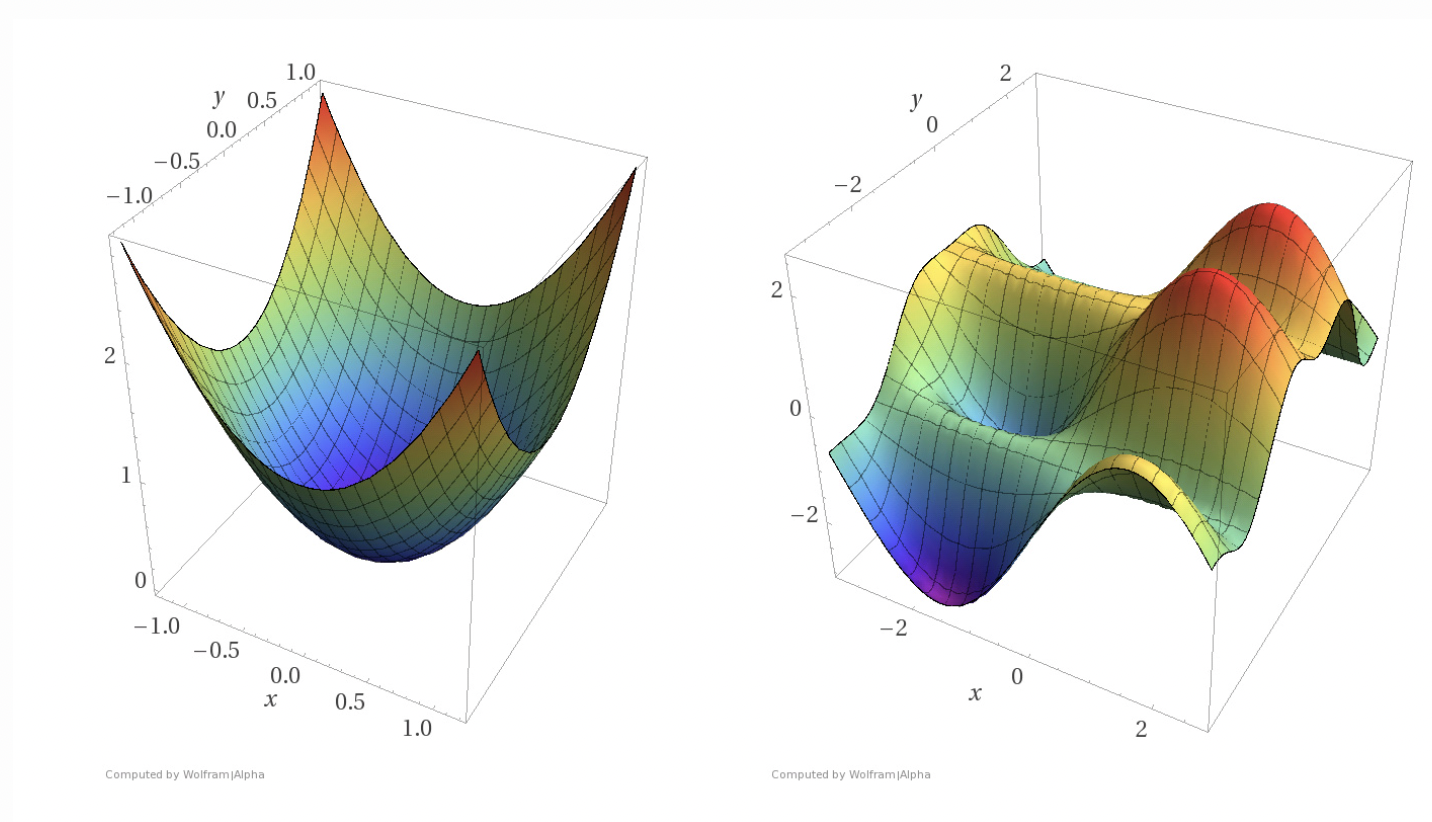
위 그림처럼 무작정 MSE 함수에 시그모이드 함수를 때려박고 미분을 하게되면 local minimum, 즉 지역국소값을 모델이 학습할때 최소값이라고 착각하게 될 수도 있기 때문에 좋지 않습니다.
우리는 전체 함수에서의 최소값, Global Minimum을 찾는 것이 목표이기 때문입니다.
시그모이드 함수의 특징으로 Classification을 할 수 있다고 소개해드렸었습니다.
보통 $f(0)$ 인 0.5를 임계값으로 설정하고 넘어가면 1(True)을 출력하고 넘지 못하면 0(False)를 출력한다고 했었습니다.
이를 조금 더 확장해서 생각해보면 만약 실제값이 1이고 예측값이 0근처라면 오차가 커야겠지요? 반대로 실제값이 0이고 예측값이 1쪽이면 오차가 커야할겁니다.
이를 만족시킬 수 있는 함수로 로그함수를 이용할 수 있습니다.
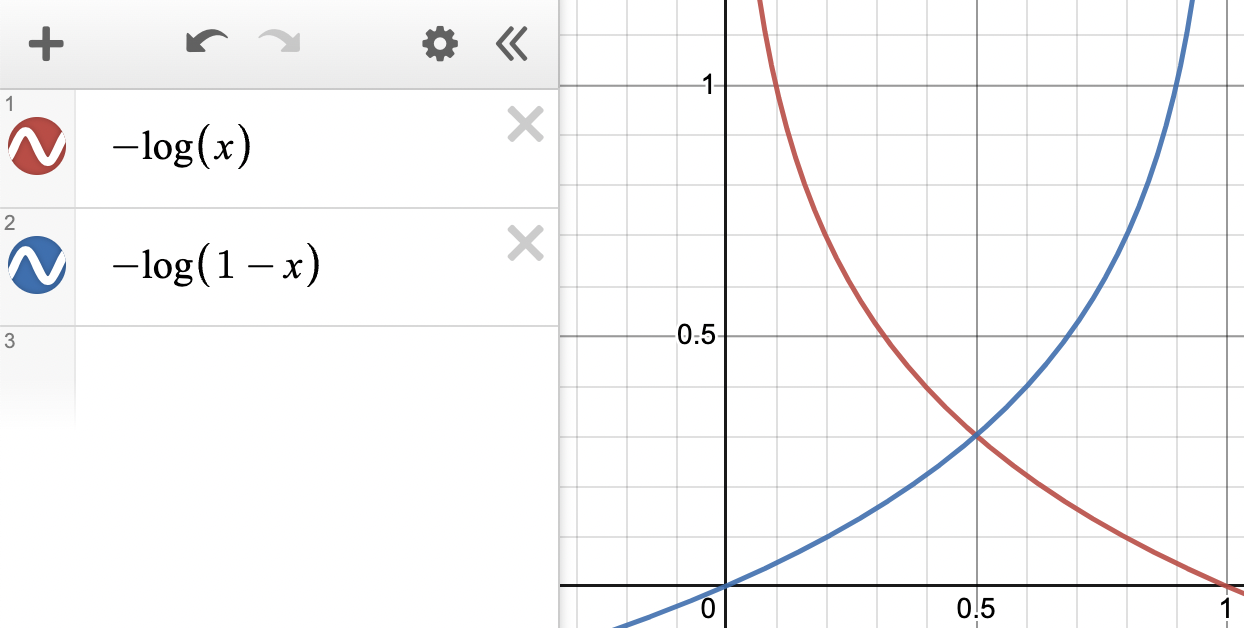
그래서 오차를 표현하기위해 실제값이 1일 때의 그래프가 $-log(x)$, 빨간그래프.
실제값이 0일 때의 그래프가 $-log(1-x)$, 파랑그래프로 나타낼 수 있습니다.
실제값이 1이라고 했을 때, 예측값도 1이라면 $-log1=0$ 이기때문에 완벽한 손실함수의 최소값이 나옵니다.
혹은 예측값이 0이라고한다면, $-log0=\infty$ 로 손실이 최대가 납니다.
반대로 실제값이 0이라고 했을 때, 예측값이 0이면 $-log(1-0)=0$ 으로 완벽한 예측을 했다고 볼 수 있고,
예측을 1이라고 했다면, $-log(1-1)=\infty$ 으로 손실이 최대가 나오게 됩니다.
그래서 저희는 이제 두 경우의 수를 모두 합치면 다음과 같다고 할 수 있습니다.
\[\text{cost}\left( H(x), y \right) = -[ylogH(x) + (1-y)log(1-H(x))]\]왜 두개의 식이 합쳐졌을까요??
이유는 H(x) 값에 0 또는 1 밖에 들어가지 않으므로 앞에서 설명했던 것 처럼 실제값이 1이라면 덧셈을 기준으로 우측항이 실제값이 0이라면 덧셈을 기준으로 좌측항이 사라지기 때문입니다.
이제 모든 오차의 평균을 구하면 손실함수는 아래와 같습니다.
\[cost(W) = -\frac{1}{n} \sum_{i=1}^{n} [y^{(i)}logH(x^{(i)}) + (1-y^{(i)})log(1-H(x^{(i)}))]\]이제 위 비용 함수를 이용하여 경사 하강법을 사용하면 최적의 W 와 b 값을 찾을 수 있습니다.
\[W := W - α\frac{∂}{∂W}cost(W)\]
파이토치로 로지스틱 회귀 구현하기
이제 우리는 파이토치로 다수의 x 로부터 y를 예측하는 다중 로지스틱 회귀를 구현해봅시다.
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
torch.manual_seed(1)
x_train과 y_train을 텐서로 선언합니다.
x_data = [[1, 2], [2, 3], [3, 1], [4, 3], [5, 3], [6, 2]]
y_data = [[0], [0], [0], [1], [1], [1]]
x_train = torch.FloatTensor(x_data)
y_train = torch.FloatTensor(y_data)
앞서 훈련 데이터를 행렬로 선언하고, 행렬 연산으로 가설을 세우는 방법을 배웠습니다.
여기서도 마찬가지로 행렬 연산을 사용하여 가설식을 세울겁니다. x_train과 y_train의 크기를 확인해봅시다.
print(x_train.shape)
print(y_train.shape)
torch.Size([6, 2])
torch.Size([6, 1])
현재 x_train은 6 × 2의 크기(shape)를 가지는 행렬이며, y_train은 6 × 1의 크기를 가지는 벡터입니다.
x_train을 $X$라고 하고, 이와 곱해지는 가중치 벡터를 $W$라고 하였을 때, $XW$가 성립되기 위해서는 벡터의 크기는 2 × 1이어야 합니다.
이제 W와 b를 선언합니다.
W = torch.zeros((2, 1), requires_grad=True) # 크기는 2 x 1
b = torch.zeros(1, requires_grad=True)
이제 가설식을 세워보겠습니다.
파이토치에서는 $e^x$를 구현하기 위해서 torch.exp(x)를 사용합니다. 이에 따라 행렬 연산을 사용한 가설식은 다음과 같습니다.
hypothesis = 1 / (1 + torch.exp(-(x_train.matmul(W) + b)))
앞서 W와 b는 torch.zeros를 통해 전부 0으로 초기화 된 상태입니다. 이 상태에서 예측값을 출력해봅시다.
print(hypothesis) # 예측값인 H(x) 출력
tensor([[0.5000],
[0.5000],
[0.5000],
[0.5000],
[0.5000],
[0.5000]], grad_fn=<MulBackward>)
실제값 y_train과 크기가 동일한 6 × 1의 크기를 가지는 예측값 벡터가 나오는데 모든 값이 0.5입니다.
사실 가설식을 좀 더 간단하게도 구현할 수 있습니다. 이미 파이토치에서는 시그모이드 함수를 이미 구현하여 제공하고 있기 때문입니다. 다음은 torch.sigmoid를 사용하여 좀 더 간단히 구현한 가설식입니다.
hypothesis = torch.sigmoid(x_train.matmul(W) + b)
앞서 구현한 식과 본질적으로 동일한 식입니다. 마찬가지로 W와 b가 0으로 초기화 된 상태에서 예측값을 출력해봅시다.
print(hypothesis)
tensor([[0.5000],
[0.5000],
[0.5000],
[0.5000],
[0.5000],
[0.5000]], grad_fn=<SigmoidBackward>)
앞선 결과와 동일하게 나오는 것을 확인할 수 있습니다.
\[cost(W) = -\frac{1}{n} \sum_{i=1}^{n} [y^{(i)}logH(x^{(i)}) + (1-y^{(i)})log(1-H(x^{(i)}))]\]이제 이 손실 함수를 생각하며, 이를 코드로 구현해보겠습니다.
모든 원소에 대한 오차는 다음과 같습니다.
losses = -(y_train * torch.log(hypothesis) +
(1 - y_train) * torch.log(1 - hypothesis))
print(losses)
tensor([[0.6931],
[0.6931],
[0.6931],
[0.6931],
[0.6931],
[0.6931]], grad_fn=<NegBackward>)
그리고 이 전체 오차에 대한 평균을 구합니다.
cost = losses.mean()
print(cost)
tensor(0.6931, grad_fn=<MeanBackward1>)
결과적으로 얻은 cost는 0.6931입니다.
지금까지 비용 함수의 값을 직접 구현하였는데, 사실 파이토치에서는 로지스틱 회귀의 비용 함수를 이미 구현해서 제공하고 있습니다.
사용 방법은 torch.nn.functional as F와 같이 임포트 한 후에 F.binary_cross_entropy(예측값, 실제값)과 같이 사용하면 됩니다.
F.binary_cross_entropy(hypothesis, y_train)
tensor(0.6931, grad_fn=<BinaryCrossEntropyBackward>)
앞선 예제에서 다 같은 값이 나온 이유는 optimizer 함수를 통해 W 와 b값이 변화하지 않았기 때문입니다.
이제 학습까지하는 전체 코드를 살펴보겠습니다.
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
torch.manual_seed(1)
x_data = [[1, 2], [2, 3], [3, 1], [4, 3], [5, 3], [6, 2]]
y_data = [[0], [0], [0], [1], [1], [1]]
x_train = torch.FloatTensor(x_data)
y_train = torch.FloatTensor(y_data)
# 모델 초기화
W = torch.zeros((2, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
# optimizer 설정
optimizer = optim.SGD([W, b], lr=1)
nb_epochs = 1000
for epoch in range(nb_epochs + 1):
# Cost 계산
hypothesis = torch.sigmoid(x_train.matmul(W) + b)
cost = -(y_train * torch.log(hypothesis) +
(1 - y_train) * torch.log(1 - hypothesis)).mean()
# cost로 H(x) 개선
optimizer.zero_grad()
cost.backward()
optimizer.step()
# 100번마다 로그 출력
if epoch % 100 == 0:
print('Epoch {:4d}/{} Cost: {:.6f}'.format(
epoch, nb_epochs, cost.item()
))
Epoch 0/1000 Cost: 0.693147
... 중략 ...
Epoch 1000/1000 Cost: 0.019852
손실 함수값이 작아지고 있는 것을 확인할 수 있습니다. 성공!!
nn.module 로 구현하는 로지스틱 회귀
앞서 행했던 코드들을 더욱 간단하게 실행할 수 있습니다. 거의 비슷하지만 조금의 차이가 있습니다.
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
torch.manual_seed(1)
x_data = [[1, 2], [2, 3], [3, 1], [4, 3], [5, 3], [6, 2]]
y_data = [[0], [0], [0], [1], [1], [1]]
x_train = torch.FloatTensor(x_data)
y_train = torch.FloatTensor(y_data)
여기까지는 동일합니다. 이제 새롭게 등장하는 nn.Sequential()은 nn.Module 층을 차례로 쌓을 수 있도록 한다고 합니다.
후에 더 자세히 알아봐야겠습니다…
model = nn.Sequential
(
nn.Linear(2, 1), # input_dim = 2, output_dim = 1
nn.Sigmoid() # 출력은 시그모이드 함수를 거친다
)
현재 W와 b는 랜덤 초기화가 된 상태입니다. 훈련 데이터를 넣어 예측값을 확인해봅시다.
model(x_train)
tensor([[0.4020],
[0.4147],
[0.6556],
[0.5948],
[0.6788],
[0.8061]], grad_fn=<SigmoidBackward>)
6 × 1 크기의 예측값 텐서가 출력됩니다. 그러나 현재 W와 b는 임의의 값을 가지므로 현재의 예측은 의미가 없습니다.
이제 경사 하강법을 사용하여 훈련해보겠습니다. 총 100번의 에포크를 수행합니다.
# optimizer 설정
optimizer = optim.SGD(model.parameters(), lr=1)
nb_epochs = 1000
for epoch in range(nb_epochs + 1):
# H(x) 계산
hypothesis = model(x_train)
# cost 계산
cost = F.binary_cross_entropy(hypothesis, y_train)
# cost로 H(x) 개선
optimizer.zero_grad()
cost.backward()
optimizer.step()
# 20번마다 로그 출력
if epoch % 10 == 0:
prediction = hypothesis >= torch.FloatTensor([0.5]) # 예측값이 0.5를 넘으면 True로 간주
correct_prediction = prediction.float() == y_train # 실제값과 일치하는 경우만 True로 간주
accuracy = correct_prediction.sum().item() / len(correct_prediction) # 정확도를 계산
print('Epoch {:4d}/{} Cost: {:.6f} Accuracy {:2.2f}%'.format( # 각 에포크마다 정확도를 출력
epoch, nb_epochs, cost.item(), accuracy * 100,
))
각 에포크마다 정확도를 계산하여 정확도도 출력해보겠습니다.
Epoch 0/1000 Cost: 0.539713 Accuracy 83.33%
... 중략 ...
Epoch 1000/1000 Cost: 0.019843 Accuracy 100.00%
중간부터 정확도는 100%가 나오기 시작합니다. 기존의 훈련 데이터를 입력하여 예측값을 확인해보겠습니다.
model(x_train)
tensor([[0.0240],
[0.1476],
[0.2739],
[0.7967],
[0.9491],
[0.9836]], grad_fn=<SigmoidBackward>)
0.5를 넘으면 True, 그보다 낮으면 False로 간주합니다.
실제값은 [[0], [0], [0], [1], [1], [1]]입니다.
이는 False, False, False, True, True, True에 해당되므로 전부 실제값과 일치하도록 예측한 것을 확인할 수 있습니다.
훈련 후의 W와 b의 값을 출력해보겠습니다.
print(list(model.parameters()))
[Parameter containing:
tensor([[3.2534, 1.5181]], requires_grad=True), Parameter containing:
tensor([-14.4839], requires_grad=True)]
Class로 구현하는 로지스틱 회귀
앞서 보여드렸던 코드와 모두 동일하나 딱 한 부분에 있어서 차이가 납니다. 바로
model = nn.Sequential(
nn.Linear(2, 1), # input_dim = 2, output_dim = 1
nn.Sigmoid() # 출력은 시그모이드 함수를 거친다
)
이 부분이 이제 클래스로 다음과 같이 표현할 수 있습니다.
class BinaryClassifier(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(2, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
return self.sigmoid(self.linear(x))
위와 같은 클래스를 사용한 모델 구현 형식은 대부분의 파이토치 구현체에서 사용하고 있는 방식으로 반드시 숙지할 필요가 있습니다.
클래스(class) 형태의 모델은 nn.Module 을 상속받습니다. 그리고 init()에서 모델의 구조와 동적을 정의하는 생성자를 정의합니다.
이는 파이썬에서 객체가 갖는 속성값을 초기화하는 역할로, 객체가 생성될 때 자동으호 호출됩니다.
super() 함수를 부르면 여기서 만든 클래스는 nn.Module 클래스의 속성들을 가지고 초기화 됩니다.
foward() 함수는 모델이 학습데이터를 입력받아서 forward 연산을 진행시키는 함수입니다.
이 forward() 함수는 model 객체를 데이터와 함께 호출하면 자동으로 실행이됩니다. 예를 들어 model이란 이름의 객체를 생성 후, model(입력 데이터)와 같은 형식으로 객체를 호출하면 자동으로 forward 연산이 수행됩니다.
- $H(x)$ 식에 입력 $x$ 로부터 예측된 $y$를 얻는 것을 forward 연산이라고 합니다.
참고문헌 : wikidocs
댓글남기기