
Lec 07-2: Learning Rate, Overfitting, Regularization
딥러닝 공부 9일차
Learning Rate
이전에 우리 딥러닝 공부 3일차 글에서 학습률에 대해서 다뤘습니다. 한번 보고 오시면 좋을 것 같습니다.
딥러닝 공부 3일차 👈 클릭!
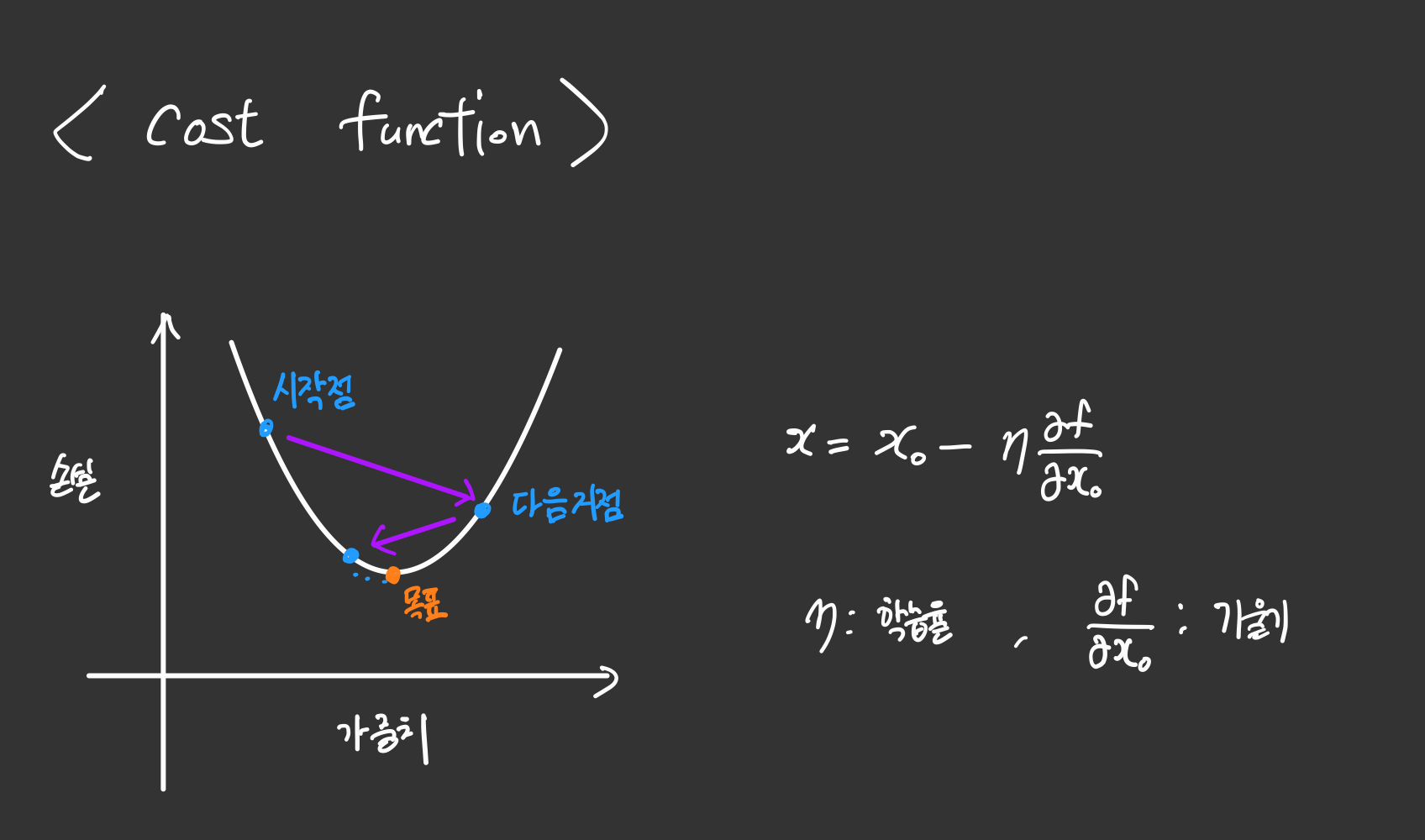
손실함수의 작동원리
Learning Rate 에 대해서 조금 더 자세히 알아보겠습니다.
\[W := W - α\frac{∂}{∂W}cost(W)\]위 그림과 달리 여기 식에서는 $\alpha$가 학습률을 나타내고 있습니다.
공부했던 내용을 되짚어봅시다. 첫 가중치와 편향은 랜덤으로 설정 되었었다는 것을 기억하시나요?
우리의 목표는 Cost function의 최소값을 찾는 것입니다.
일단 2차원으로만 생각해봅시다.
손실 함수 상의 임의의 시작점에서의 미분 값을 구합니다. 그 지점에서의 미분계수가 음수라면 현위치가 최저점 기준으로 좌측에 있다는 것을 의미하므로, 우측으로 이동해야 최저점으로 다가가게 될 것입니다.
\[W-\alpha (음수)cost(W)\]구한 기울기의 음수 값에 -가 또 있으니 결과적으로 양수가됩니다. 이는 현위치 W에서 우측으로 이동하라는 식이 됩니다.
그렇다면 이제 한번 이동했다고 해봅시다, 이동하고 난 자리가 최저점 기준으로 이번엔 우측, 즉 미분계수가 양수인 부분이라고 생각해봅시다.
\[W-\alpha (양수)cost(W)\]양수인 미분계수를 빼주게 되면 현위치에서 좌측으로 이동하게됩니다.
이런식으로 n번의 이동을 거치다보면 거의 값이 변하지 않는 값으로 수렴하게 되는데, 이부분이 최저점이 된다고 생각할 수 있겠습니다.
학습률의 작동 원리
이제 이동은하는데, 한번 이동을 할 때 얼마나 이동을하게 될까요? 이를 담당하는 것이 바로 학습률입니다.
학습률은 너무 크다고 혹은 작다고 좋은 것이 아니라 적당해야합니다. 적당한 값은 직접 모델을 학습시켜보면서 찾아나가야할 것입니다. 방법에 관한 내용은 추후에 배우게 됩니다.
Overshooting
자, 일단 학습률이 너무 큰 경우를 생각해봅시다.
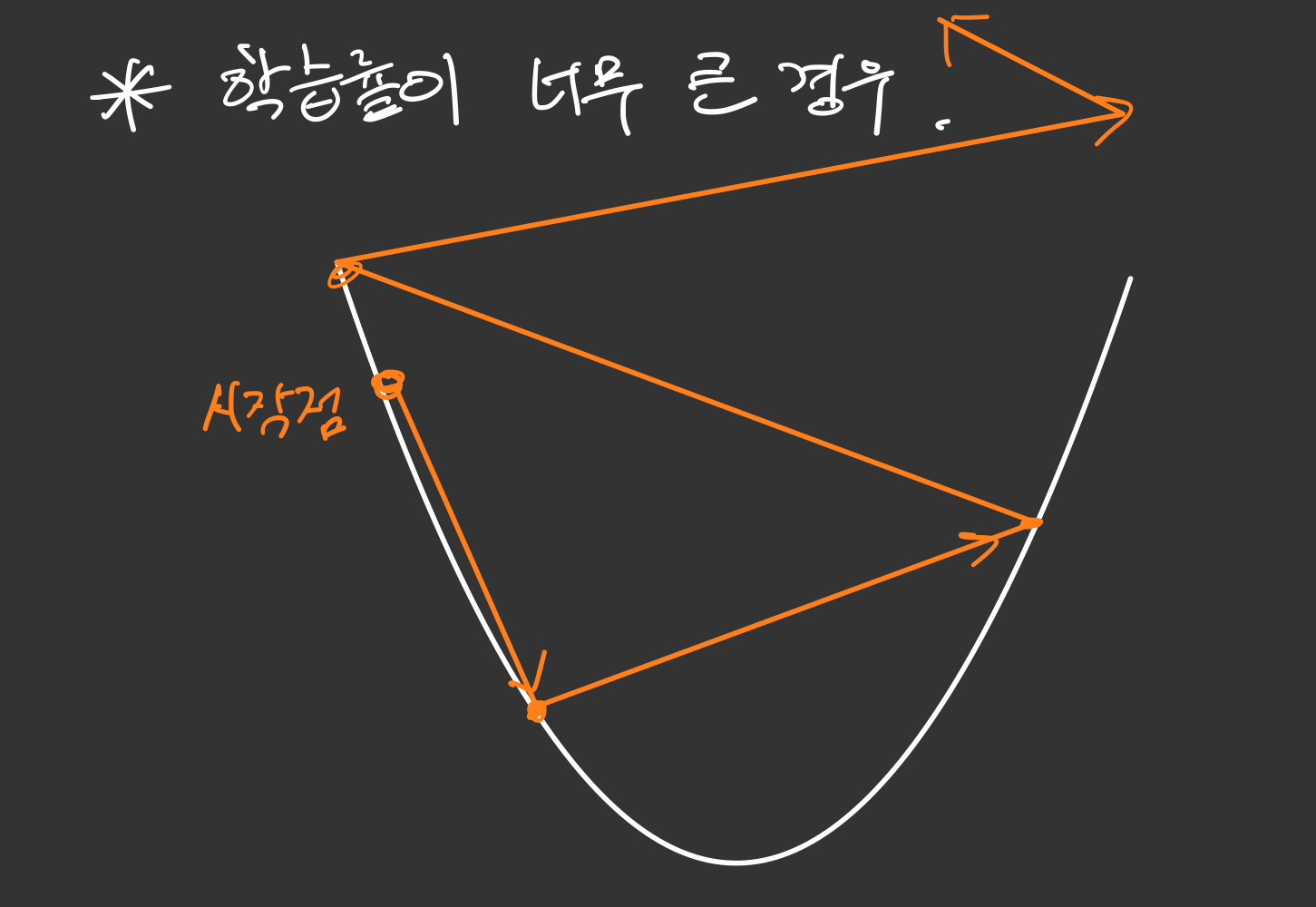
예를 들어 그림으로 표현해보았습니다. 학습률이 너무 크다면 한번에 이동하는 보폭이 클 것입니다. 그러다보면 다음 지점으로 이동한 그 미분계수의 영향을 크게 받게되겠지요.
그렇게 이동하다보면 최저점으로 이동하는 것이 아닌, 점점 바깥으로 나가버리는 발산하는 경우가 생길 수 있습니다.
이를 Overshooting 이라고 표현합니다.
Local minimum
이번에는 학습률이 너무 작은 경우를 생각해봅시다.
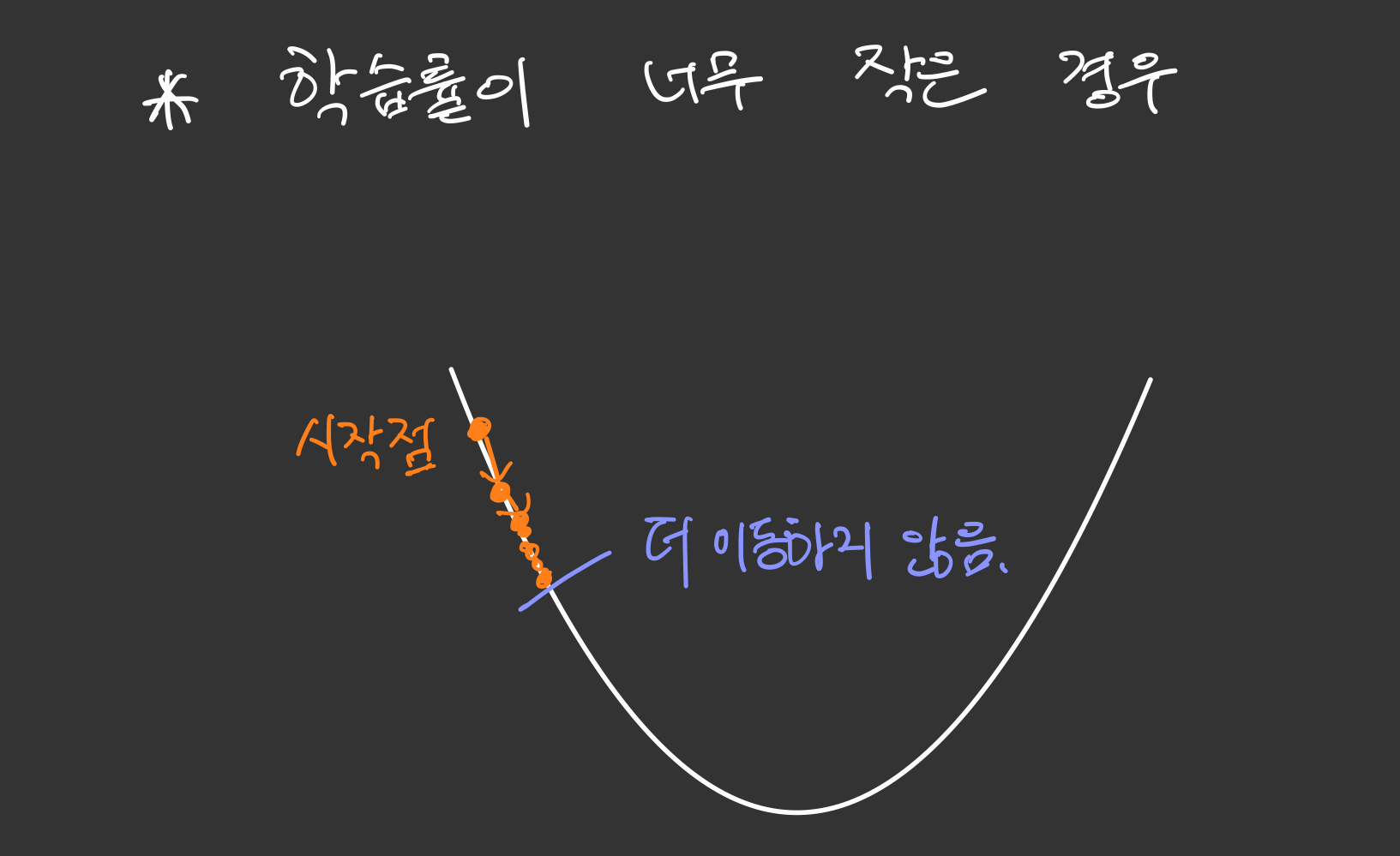
예를 들어 그림으로 표현해보았습니다. 학습률이 너무 작다면 한번에 이동하는 보폭이 너무 작을 것입니다.
학습률이 너무 작은 경우에는, 운좋게 최저점을 찾더라도 그 계산하는 과정이 너무너무 오래 걸릴 수 있습니다.
또한 그림처럼 국부적인 최소값에 빠져서 더이상 이동하지 못하는 경우가 생길 수도 있습니다.
Overfitting(과적합)
우리는 그동안 손실함수의 최소값, 가능도함수의 최대값을 구하려고 부단히 노력을 해왔습니다.
그러다보니 과적합이라는 overfitting을 피할 수가 없게 되는데요, 과적합이란 머신이 학습데이터에만 너무 국한되게 학습을 해버리는 경우를 말하게 됩니다.
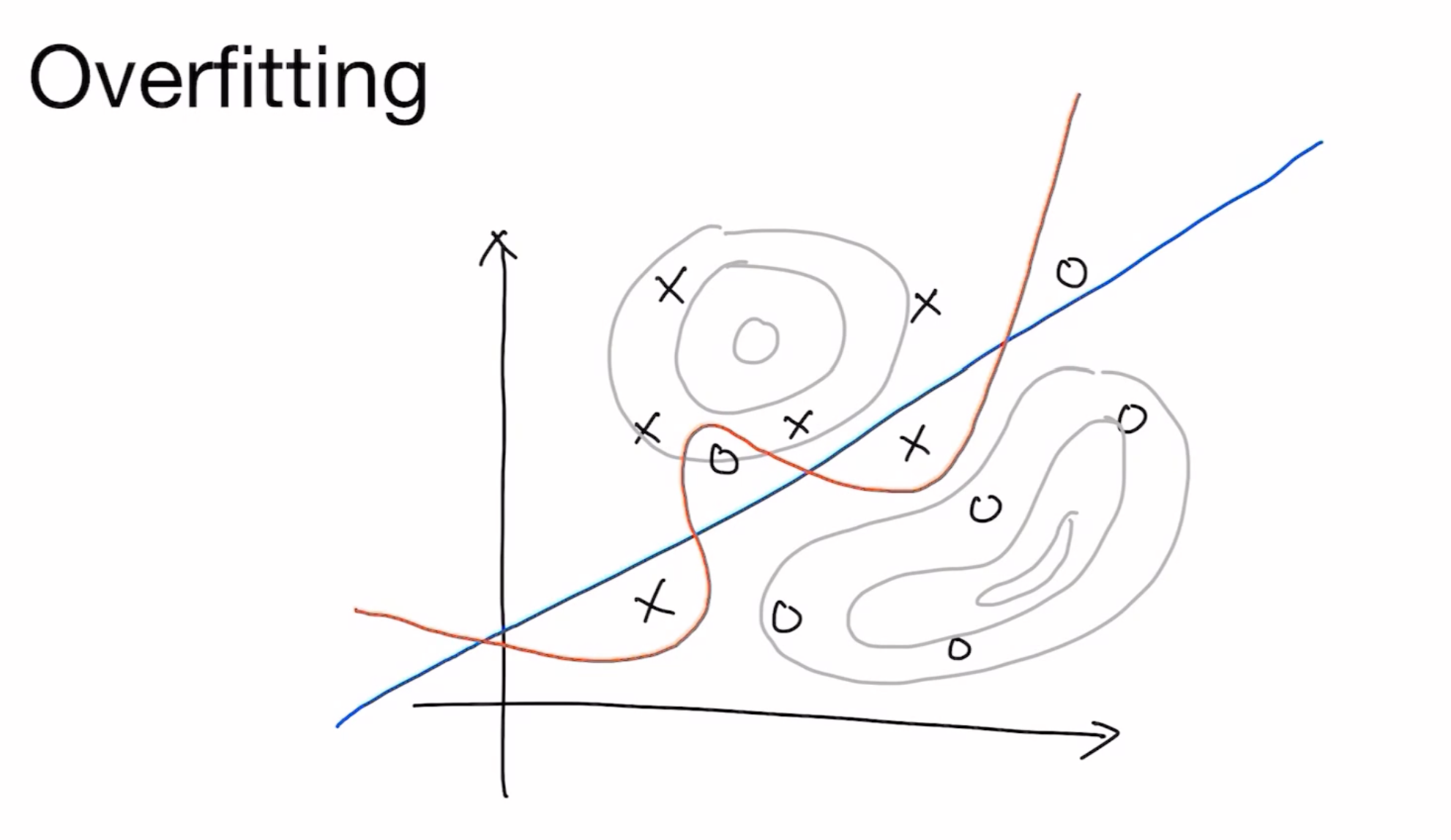
가령 O 혹은 X를 구분하는 Classification에서 다음과 같은 사진처럼 파랑색 직선 정도가 적당히 알맞은 구분선인 반면
과적합의 경우는 조금조금의 오차까지도 완벽히 분리해버리는 구불구불한 빨간색 선이라고 할 수 있겠습니다.
이는 주어진 학습데이터에만 국한된 선이기 때문에 새로운 데이터가 주어졌을 때 오류가 날 가능성이 높아지게 됩니다.
그렇다면 어떻게 과적합을 피할 수 있을까요??
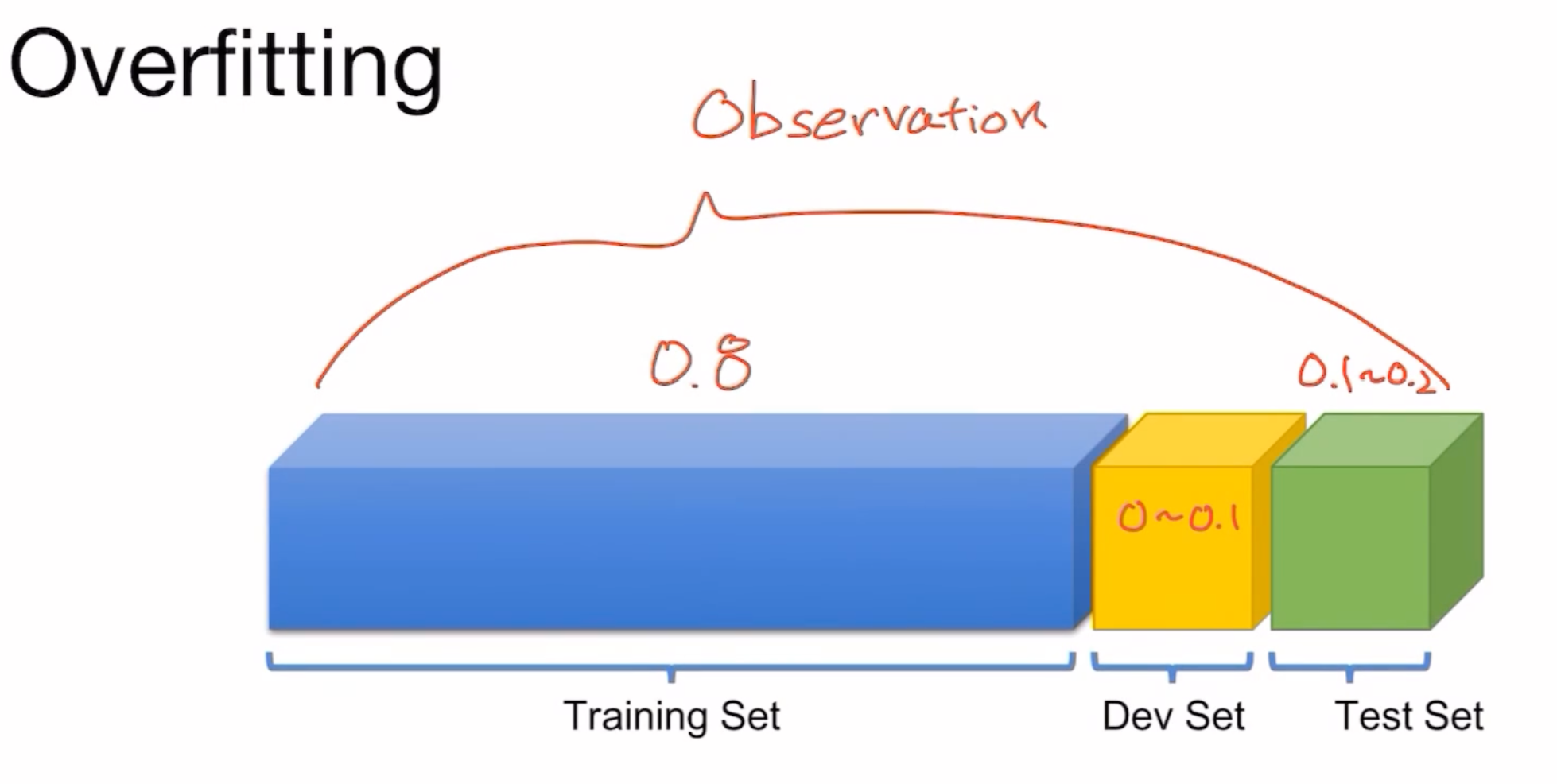
방법은 학습데이터만 머신에게 제공하는 것이 아닌, Test Set 그리고 Development Set(Validation Set) 을 제공하는 것을 방법으로 들 수 있겠습니다.
비율은 보통 Training Set을 80% 정도, Test Set을 10~20% 사용하고, Dev Set을 0~10% 정도 사용합니다.
Test Set을 통해 우리의 모델이 과적합이 되었는지 안되었는지 확인해볼 수 있습니다.
만약 Test Set도 과적합이 되어버렸다면, Dev Set이 그 부분을 해결해준다고 생각할 수 있습니다.
Overfitting을 피하는 방법이 한가지만 있는 것은 아닙니다. 여러가지 방법이 있겠지만 크게
- More Data(더 많은 데이터를 제공)
- Less features(구분할만한 특징들을 줄인다)
- Regularization

Regularization은 또 위 사진과같이 다섯가지 정도로 또 분류할 수 있습니다.
이들은 추후에 더 자세히 공부해보도록 하겠습니다.
댓글남기기