
Lec 09-1,2: NonLinear Functions & Weight Initialization
딥러닝 공부 13일차
ReLU function
시그모이드 함수의 문제점
이제 우리는 새로운 함수인 ReLU함수를 배울 것입니다. 배우기 앞서서 새로움 함수가 필요하다는 것은 기존에 쓰던 함수가 맘에 안드는 부분이 있다는 것이겠죠.
지금까지 잘 사용해왔던 시그모이드 함수의 문제점을 살펴보겠습니다.
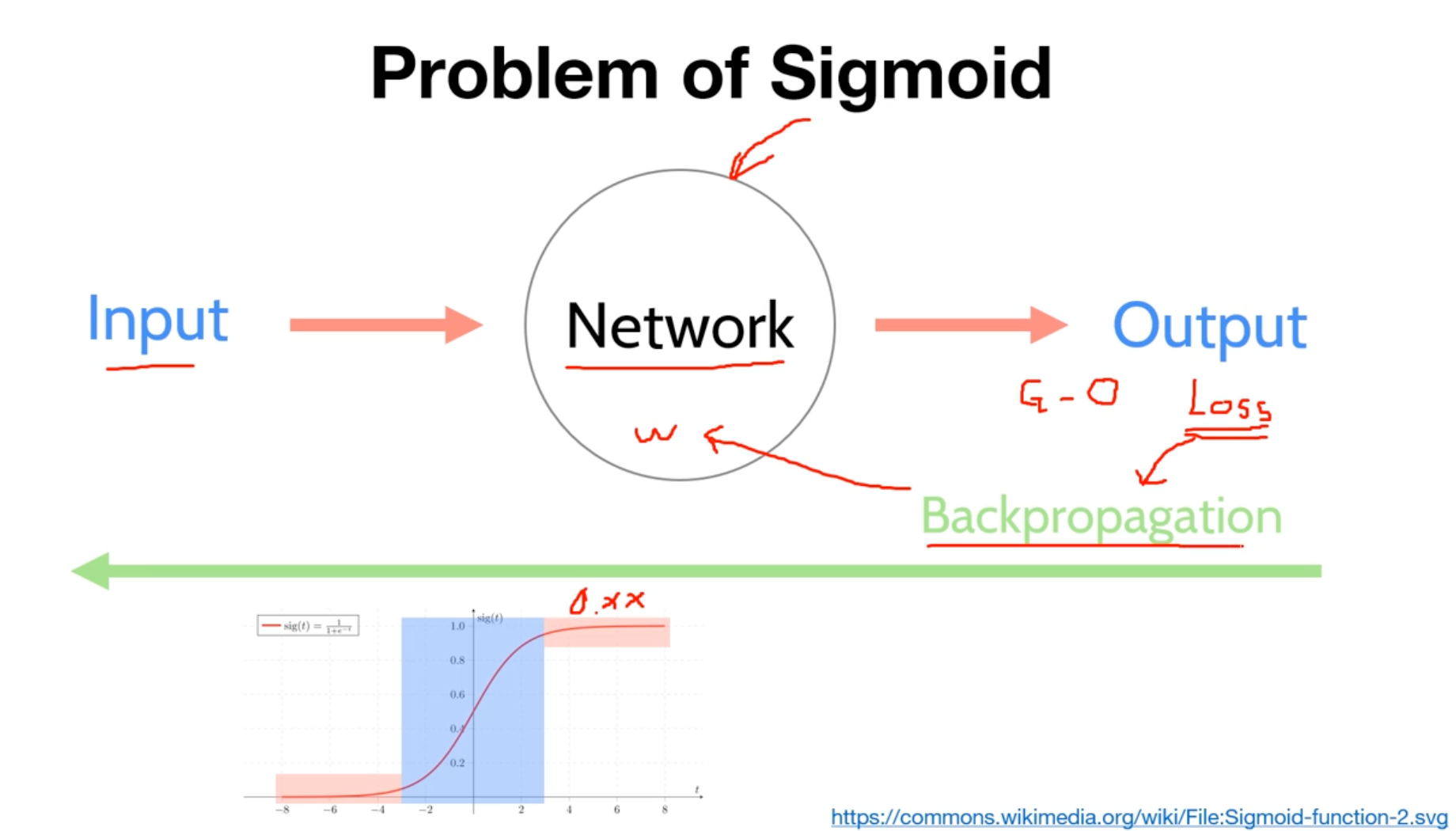
지금까지 우리는 연산과정에서 인풋데이터를 시그모이드함수를 거쳐 출력을 하게 되었었습니다. 그리고 최적의 가중치와 편향을 찾기위해 역전파방법을 사용하게 되었는데요.
이 역전파방법을 수행함에 있어서, 그림에서 시그모이드함수의 파랑색 박스 부분에서는 미분계수를 구하고 역연산하는 과정에서 문제가 발생하지 않습니다.
하지만 빨간박스테투리부근으로 가면 갈 수록, 미분계수가 0에 가까워지는 현상이 발생하게되고 이는 역전파방법을 수행하면서 점점 값이 사라지는, Vanishing Gradient 라는 현상이 발생하게 됩니다.
결론적으로 시그모이드 함수를 은닉층에서 사용하는 것은 지양하게 됩니다.
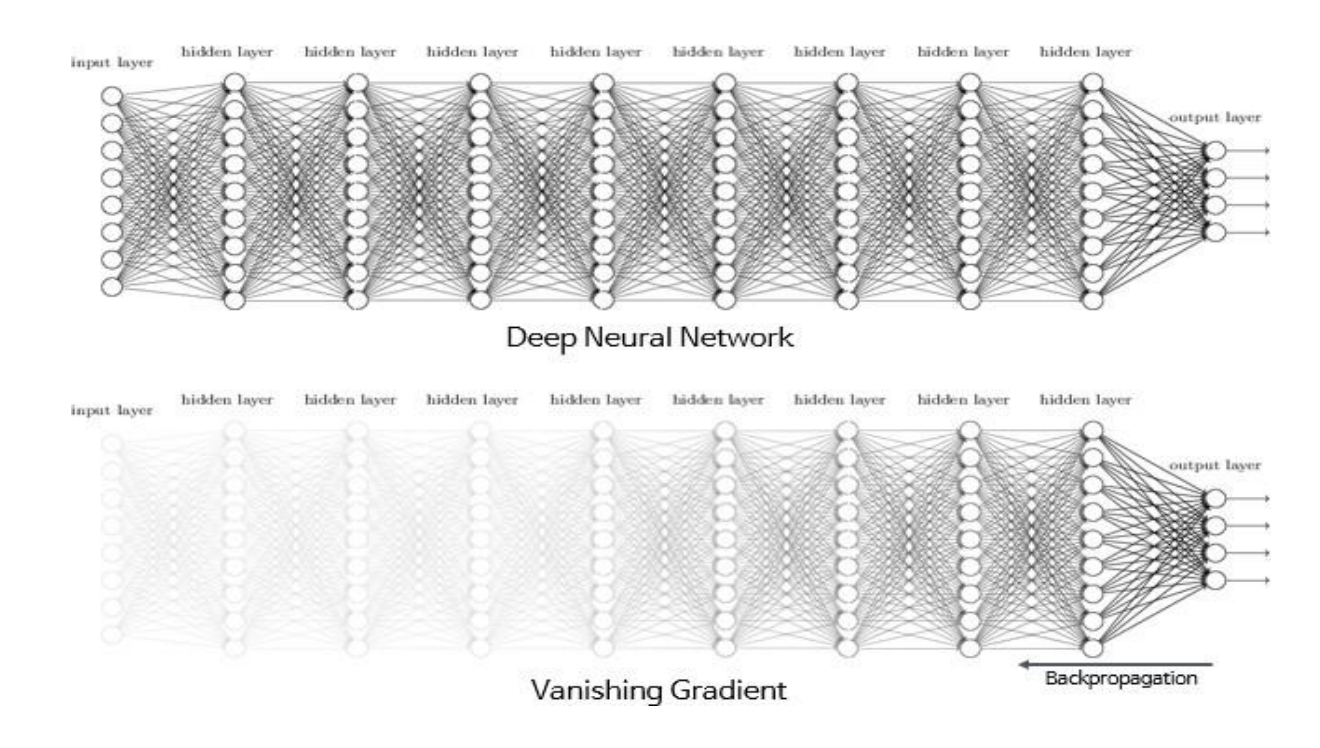
또한 시그모이드함수는 원점중심이 아니기 때문에, 출력의 가중치 합이 입력의 가중치 합보다 커질 가능성이 높습니다. 이를 편향 이동(bias shift) 라고 합니다.
그렇다면 랠루함수는 어떻게 생겼을까요?
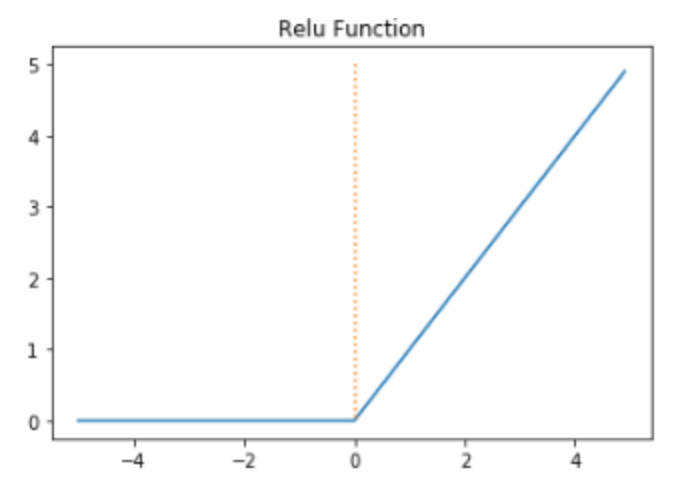
인공 신경망에서 최고의 인기를 얻고있는 함수라고합니다. 수식은 $f(x)=max(0,x)$ 로 아주 간단합니다.
렐루함수는 0 이하의 음수부터는 0을 출력하고 0부터는 항등함수 x 가 출력되는 함수입니다.
렐루함수의 장점은, 하이퍼블릭탄젠트함수나 시그모이드함수처럼 연산이 필요한 것이 아니라 단순 임계값이므로 연산 속도도 빠르고, 특정 양수값에 수렴하지 않으므로 깊은 신경망에서 훨씬 더 잘 작동하는 장점이 있습니다.
단점으로는 입력값이 음수이면 기울기가 0이 되어버리기 때문에 연산한 뉴런을 회생하는 것이 매우 어렵습니다. 이러한 문제를 죽은 렐루(dying ReLU)라고 합니다.
이제 또 다른 비선형함수들을 추가로 알아보겠습니다.
Hyperbolic tangent function(하이퍼볼릭 탄젠트 함수)
하이퍼볼릭 탄젠트 함수는 입력값을 -1과 1사이의 값으로 변환합니다.
생긴 모양은 기존의 탄젠트 함수와 형태가 아주 비슷합니다. 대신 탄젠트함수의 한주기인 $(-\frac{\pi}{2},\frac{\pi}{2})$ 가 $(-1,1)$ 로 바뀌고, 뒤접어져 누워진 형태라고 볼 수 있습니다.
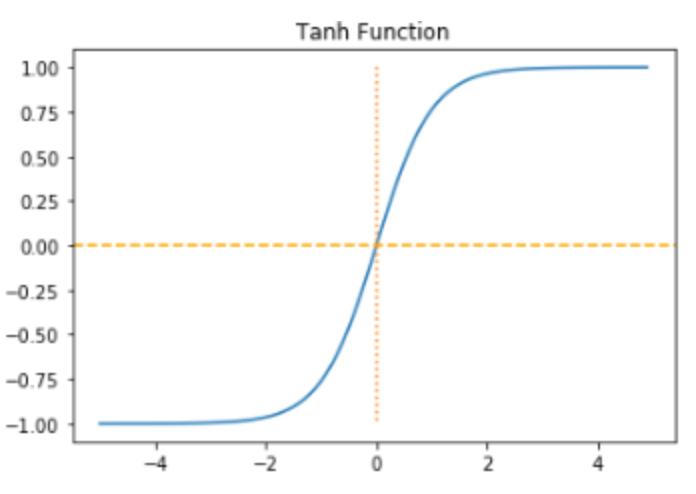
시그모이드 함수는 원점중심이 아니라는 문제점이 있었습니다. 그에비해 $tanh(x)$ 함수는 원점 중심이기 떄문에 편향이동이 발생하지 않는 점이 장점으로 꼽을 수 있겠습니다.
하지만 하이퍼볼릭 탄젠트함수도 시그모이드처럼 함수의 끝부분으로 갈 수록 기울기 소실(Vanishing Gradient)의 문제가 일어날 수 있습니다.
Softmax function
은닉층에서 렐루함수 등을 사용하는 것이 일반적이지만, 그렇다고 앞서 배운 시그모이드나 소프트맥스 함수가 사용되지 않는다는 의미가 이닙니다.
분류 문제를 로지스틱 회귀와 소프트맥스 회귀를 출력층에 적용하여 사용합니다.
소프트맥스 함수는 시그모이드 함수처럼 출력층의 뉴런에서 주로 사용되는데, 시그모이드 함수가 두 가지 선택지 중 하나를 고르는 이진 분류(Binary Classification) 문제에 사용된다면,
세 가지 이상의(상호 배타적인) 선택지 중 하나를 고르는 다중 클래스 분류(MultiClass Classificaiton) 문제에 주로 사용됩니다.
Leaky ReLU function
앞서 배웠던 렐루 함수의 문제점을 보완하기 위해 나온 함수입니다.
죽은 렐루를 보완하기 위한 다양한 렐루함수의 변형 함수들이 있습니다. 그중에 Leaky ReLU만 알아보겠습니다. 리키 렐루 함수는 입력값이 음수일 경우에 0이 아니라 아죽 작은 수를 반환하도록 되어있습니다.
수식은 $f(x)=max(ax,x)$로 아주 간단합니다. 여기서 음수인 부분의 함수의 기울기에 해당하는 a 값을 하이퍼파라미터로 새는 정도를 결정하며, 일반적으로는 0.001 값을 가집니다.
새는 정도를 확실히 보기 위해서
a = 0.1
def leaky_relu(x):
return np.maximum(a*x, x)
x = np.arange(-5.0, 5.0, 0.1)
y = leaky_relu(x)
plt.plot(x, y)
plt.plot([0,0],[5.0,0.0], ':')
plt.title('Leaky ReLU Function')
plt.show()
로 함수를 그려보면
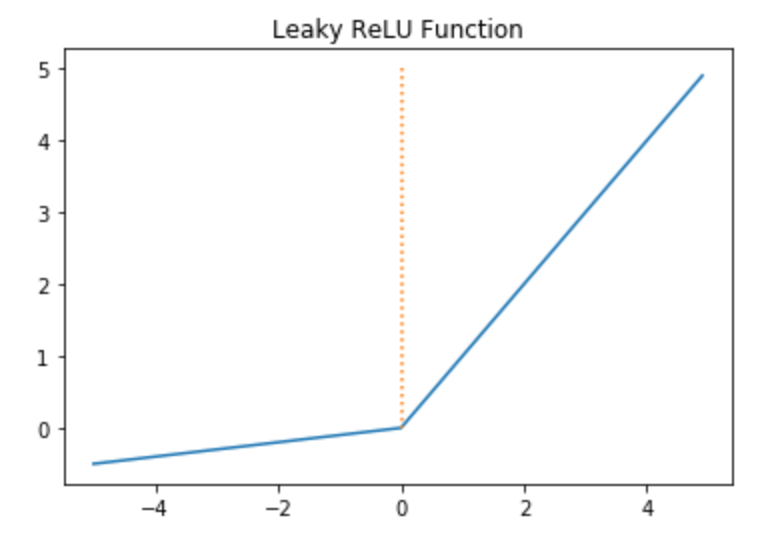
위의 그림과 같습니다~!
딥러닝 공부 14일차
Weight Initialization(가중치 초기화)
앞서 우리는 여러가지 예제들을 실행해보았습니다. 분명 같은 모델을 훈련시키는데, 예제에나 유튜브, 책에서 나왔던 수치가 동일하게 뜨지 않는 경우를 보신적이 있으실겁니다.
이는 초기에 랜덤하게 가중치와 편향을 소환하기 때문에, 각자의 노트북에서 모두 다른 결과 값이 나오게 되는 것입니다.
그래서 분명 좋은 학습률이 아니였는데도 불구하고 어떨 때는 손실 함수값이 적게 나오는 경우가 있었습니다.
다시말해 가중치가 초기에 어떤 값을 가졌느냐에 따라서 모델의 훈련 결과가 달라집니다.
가중치 초기화만 적절히 잘해주면 기울기 소실같은 문제는 방지할 수 있다는 말입니다.
그렇다면 어떻게 초기화를 진행해야 잘했다고 소문이 날까요?
- 0으로 초기화해서는 안된다!
조금만 생각해보면 당연한 이야기입니다. 우리는 머신을 학습시킬 때, BackPropagation(역전파) 방법으로, Chain Rule(연쇄 미분)을 통해 Weight(가중치)를 업데이트하게 되는데,
여기서 가중치값이 0이 되어버린다면 Gradient(기울기) 들이 0으로 다 사라져버리기 때문입니다.
- Hinton 교수님이 2006년에 Restricted Boltzmann Machine (RBM) 방식을 사용하여 가중치를 초기화해준 후 학습을 시키면 성능이 매우 개선된다는 것을 발표하셨는데요.
더 자세히 알아보겠습니다.
Restricted Boltzmann Machine(RBM)
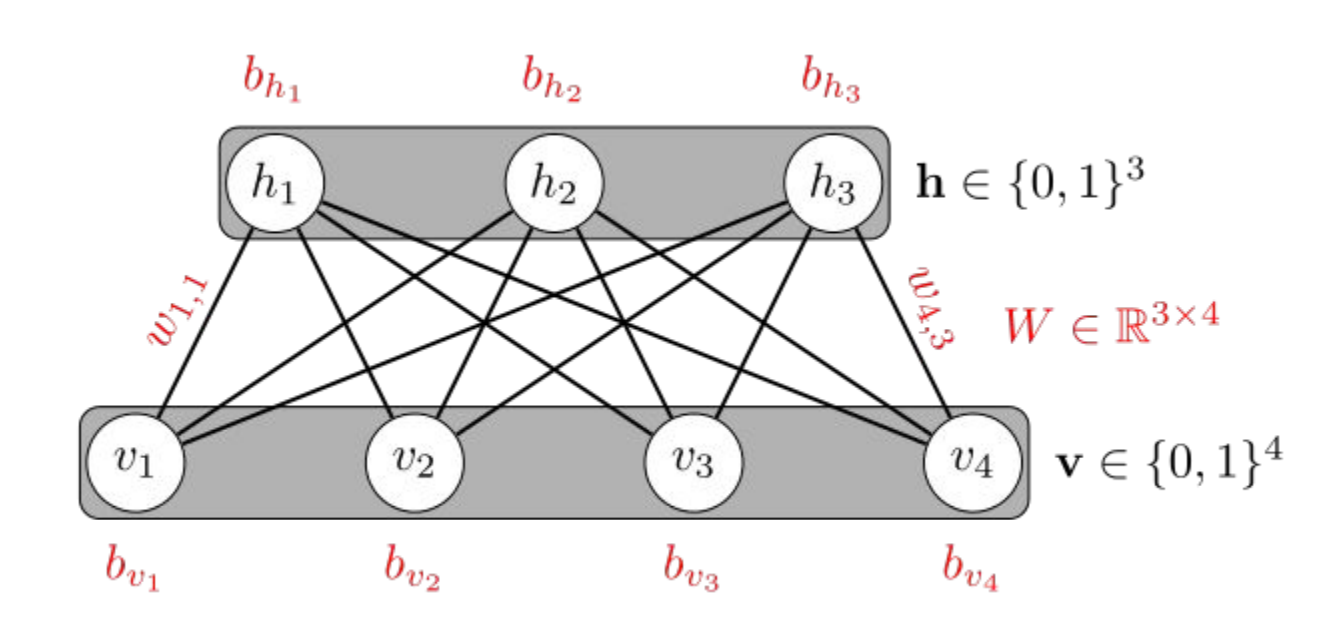
RBM은 같은 층에 있는 놈들은 연결되어있지 않고, 층과 층사이에는 모두 연결되는 구조입니다. 현재는 이 RBM 방식보다 더 간단하고 좋은 방법들이 고안이되어서 잘 사용하지는 않는다고 합니다.
그래도 배우는 입장이니까 어떻게 초기화를 하는지 알아보겠습니다.
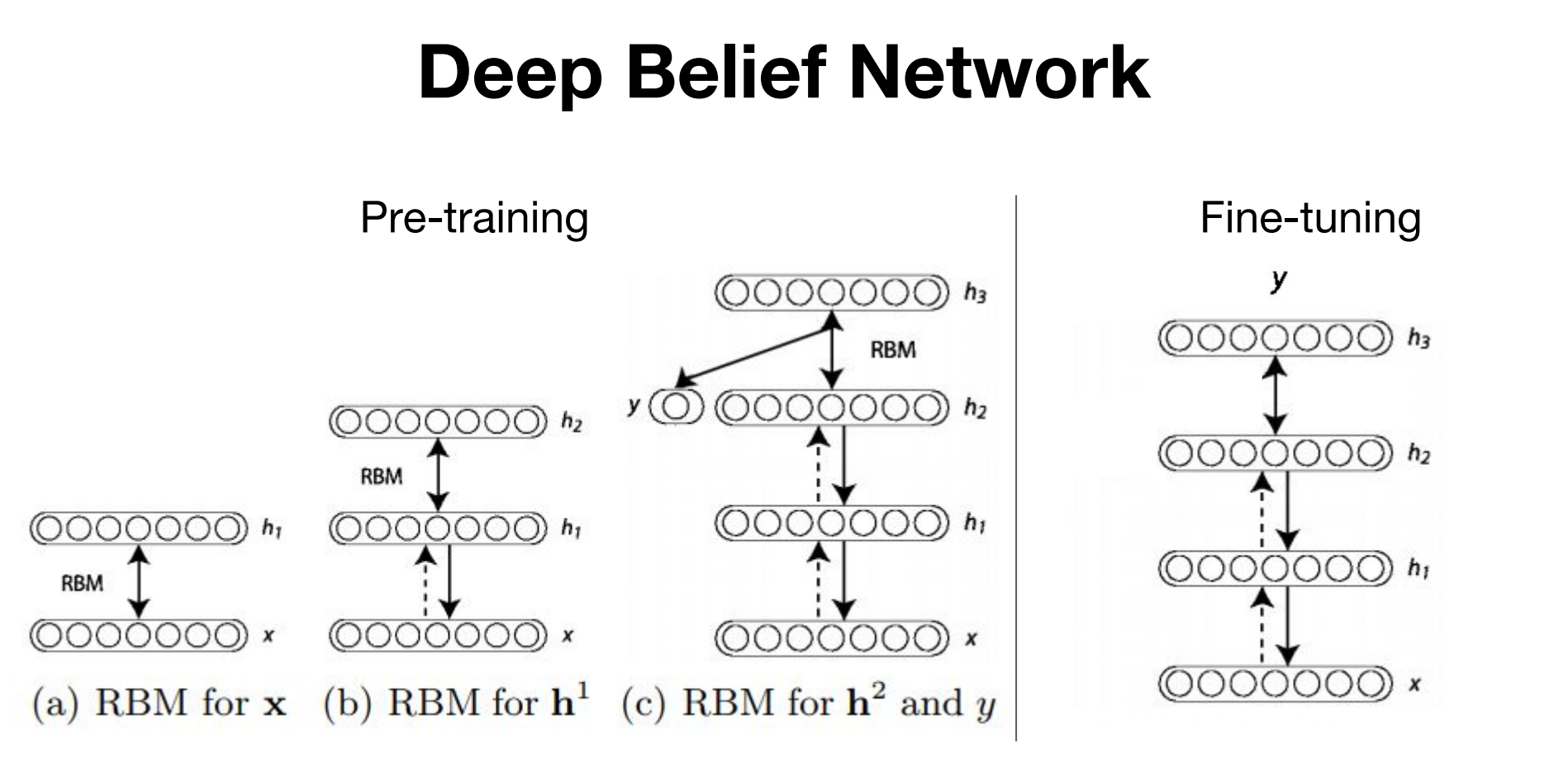
맨처음 입력층과 첫 은닉층 사이에서의 Forward 와 Backword 연산을 마치고 나온 가중치들을 고정을 시킵니다.
그 다음 첫번째 은닉층과 두번째 은닉층 사이에서 연산을 해주고 고정
그 다음 그 다음… 이런식으로 층과 층사이 하나씩 Pre-training을 시켜주고나서
출력층까지의 학습을 마치면 RBM 방식을 사용했다고 할 수 잇는 것입니다.

Xavier Initialization(세이비어 초기화)
이 초기화 방법을 고안한 사람의 이름을 따서 세이비어 초기화 혹은 글로럿 초기화라고도 합니다.
이 방법은 균등 분포(Uniform Distribution) 혹은 정규 분포(Normal Distribution)로 초기화 할 때 두 가지 경우로 나뉩니다.
$n_{in}$은 이전층의 뉴런의 개수를, $n_{out}$를 다음층의 뉴런의 개수라고 하면
먼저 균등 분포는 다음과 같습니다. \(W \sim Uniform(-\sqrt{\frac{6}{ {n}_{in} + {n}_{out} }}, +\sqrt{\frac{6}{ {n}_{in} + {n}_{out} }})\)
$\sqrt{\frac{6}{ {n}{in} + {n}{out} }}$를 m이라고 하였을 때, -m 과 m 사이의 균등 분포를 의미합니다.
정규 분포로 초기화한 경우는 평균이 0이고, 표준편차가 $\sigma$가 다음을 만족하도록 합니다.
\[σ=\sqrt{\frac { 2 }{ { n }_{ in }+{ n }_{ out } } }\]정규분포는 $X \sim N(0,\sigma^2)$ 으로 표현합니다.
세이비어 초기화는 특정 층이 너무 주목을 받거나 뒤쳐지는 것을 방지합니다. 그리고 세이비어 초기화는 시그모이드함수나 하이퍼볼릭탄젠트함수와 같은 S자 형태인 활성화 함수와 사용할 때는 좋은 성능을 보이지만, ReLU와 함께 사용할 때는 성능이 좋지 않습니다.
ReLU함수와 잘 어울리는 것은 He 초기화 방법이 있습니다.
He Initialization
He 초기화방법은 세이비어 방법과 다르게 다음층의 뉴런의 개수를 고려하지 않습니다.
균등 분포로 고려할 때는 다음과 같습니다.
\[W\sim Uniform(- \sqrt{\frac { 6 }{ { n }_{ in } } } , \space\space + \sqrt{\frac { 6 }{ { n }_{ in } } } )\]정규 분포로 초기화할 경우에는 표준 편차 $\sigma$ 가 다음을 만족하도록 합니다.
\[σ=\sqrt{\frac { 2 }{ { n }_{ in } } }\]
댓글남기기