
Lec 10-3 : VGG, Advance CNN
딥러닝 공부 22일차
VGG-net
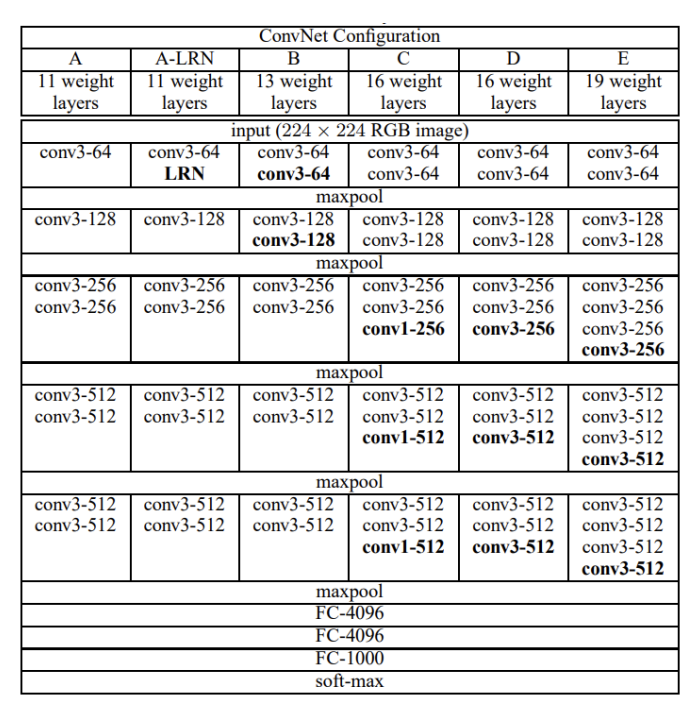
Oxford VGG(Visual Geometry Group) 에서 만든 Network입니다.
VGG는 Layer의 개수에 따라 VGG11 ~ VGG19 까지 만들 수 있도록 되어있습니다. torchvision.models.vgg 로 사용할 수 있습니다.
또한 3224224 입력을 기준으로 만들도록 되어 있습니다.
VGG 코드 구현

모두 3*3 Conv, Stride = 1, Padding = 1 로 이루어져있어서 구조가 어려운 편은 아닙니다.
import torch.nn as nn
import torch.utils.model_zoo as model_zoo
__all__ = [
'VGG', 'vgg11', 'vgg11_bn', 'vgg13', 'vgg13_bn', 'vgg16', 'vgg16_bn',
'vgg19_bn', 'vgg19',
]
model_urls = {
'vgg11': 'https://download.pytorch.org/models/vgg11-bbd30ac9.pth',
'vgg13': 'https://download.pytorch.org/models/vgg13-c768596a.pth',
'vgg16': 'https://download.pytorch.org/models/vgg16-397923af.pth',
'vgg19': 'https://download.pytorch.org/models/vgg19-dcbb9e9d.pth',
'vgg11_bn': 'https://download.pytorch.org/models/vgg11_bn-6002323d.pth',
'vgg13_bn': 'https://download.pytorch.org/models/vgg13_bn-abd245e5.pth',
'vgg16_bn': 'https://download.pytorch.org/models/vgg16_bn-6c64b313.pth',
'vgg19_bn': 'https://download.pytorch.org/models/vgg19_bn-c79401a0.pth',
}
위 링크들은 Pytorch에서 Pre-training 시켜놓은 모델들입니다.
class VGG(nn.Module):
def __init__(self, features, num_classes=1000, init_weights=True):
super(VGG, self).__init__()
self.features = features #convolution
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, num_classes),
)#FC layer
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.features(x) #Convolution
x = self.avgpool(x) # avgpool
x = x.view(x.size(0), -1) #
x = self.classifier(x) #FC layer
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
VGG 클래스입니다.
- Pytorch에서 Class 형태의 모델은 항상 nn.Module을 상속 받아야하고, super(모델명,self).init()을 통해 nn.Module.init()을 실행시키는 코드가 필요합니다.
- forward()는 모델이 학습 데이터를 입력 받아서 forward prop을 진행시키는 함수입니다.
- self.modules() : 모델 클래스에서 정의된 Layer들을 iterable(객체)로 차례로 반환
- instance() : 차례로 Layer를 입력하여, Layer형태를 반환
- nn.init.kaiming_normal : he initaialization의 한 종류
- torch.nn.init.constant_(tensor, val) : tensor를 val로 초기화
- torch.nn.init.normal_(tensor, mean=0.0, std=1.0) : tensor를 평균0, 표준편차1인 정규분포로 초기화
def make_layers(cfg, batch_norm=False):
layers = []
in_channels = 3
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)
cfg 값에 따라 layer들이 반복문을 통헤 차례로 쌓여지는 코드입니다.
- 숫자(output channel)가 들어올 경우, Conv2d 진행, 출력채널값이 입력채널값으로 바뀜
- M 이 들어올경우 Max Pooling 진행
cfg = {
'A': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'], #8 + 3 =11 == vgg11
'B': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'], # 10 + 3 = vgg 13
'D': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'], #13 + 3 = vgg 16
'E': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'], # 16 +3 =vgg 19
'custom' : [64,64,64,'M',128,128,128,'M',256,256,256,'M']
}
feature = make_layers(cfg['A'], batch_norm=True)
CNN = VGG(feature, num_classes=10, init_weights=True)
CNN
위와 같이 입력한 결과 값은
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(5): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(6): ReLU(inplace=True)
(7): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(8): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(9): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(10): ReLU(inplace=True)
(11): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(12): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(13): ReLU(inplace=True)
(14): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(15): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(16): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(17): ReLU(inplace=True)
(18): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(19): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(20): ReLU(inplace=True)
(21): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(22): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(23): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(24): ReLU(inplace=True)
(25): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(26): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(27): ReLU(inplace=True)
(28): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))
(avgpool): AdaptiveAvgPool2d(output_size=7)
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=10, bias=True)
)
)
댓글남기기