
Lec 11-1 : RNN basics
딥러닝 공부 25일차

RNN을 Pytorch에서 구동하는 법은 두줄이면 끝납니다.
그림에서 볼 수 있듯이
rnn = torch.nn.RNN(input_size, hidden_size)
outputs, _status = rnn(input_data)
Input_data shape
위처럼 두줄이면 rnn을 가져다 쓸 수 있습니다. 이제 여기서 input data의 모양이 어떻게 구성이되는지, output shape도 어떻게 이루어져 있는지 알아보겠습니다.
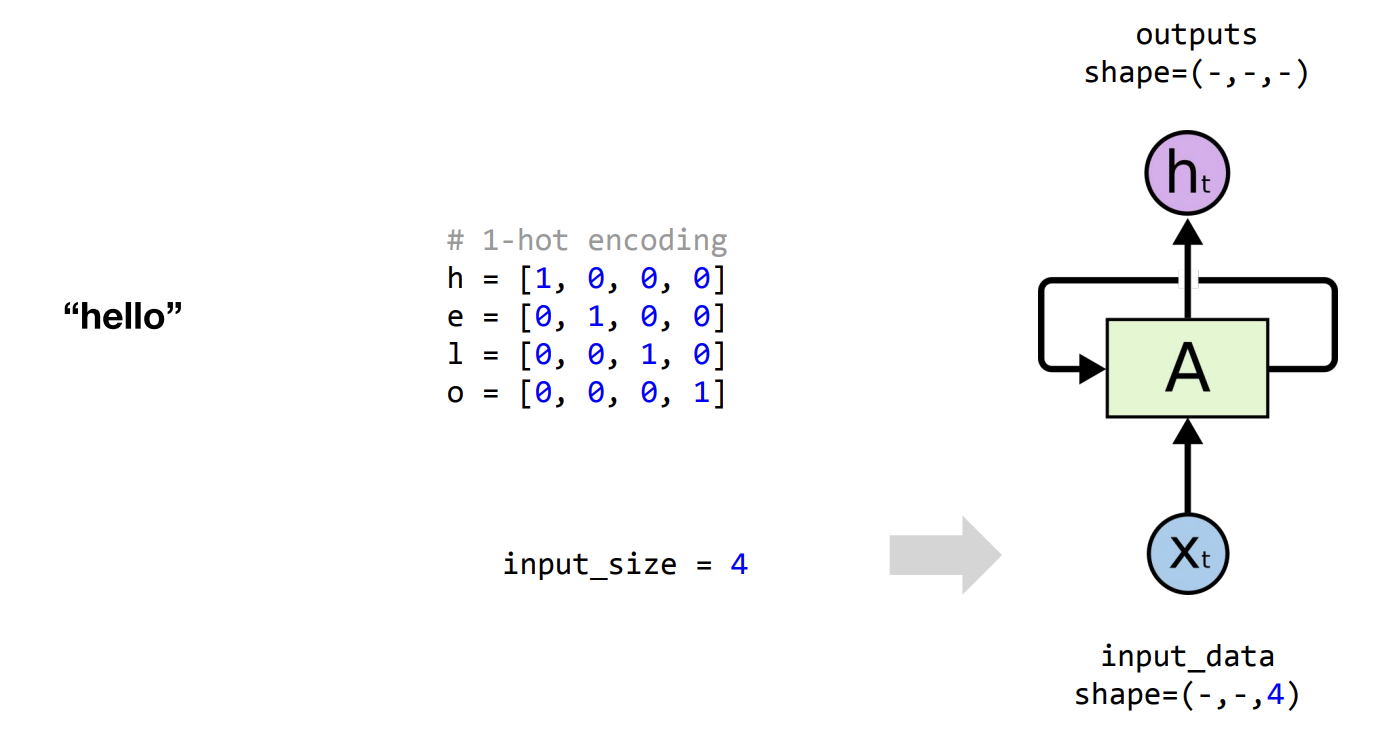
Input_size
우리가 살펴볼 글자는 hello 입니다.
여기서 글자수는 5개지만 실제로 사용되는 글자는 h, e, l, o 이렇게 4가지이므로, (-, -, 4) 괄호 안에들어가는 3가지중 맨 오른쪽에는 사용되는 글자 자체의 개수가 들어가게 됩니다.
Sequence Length
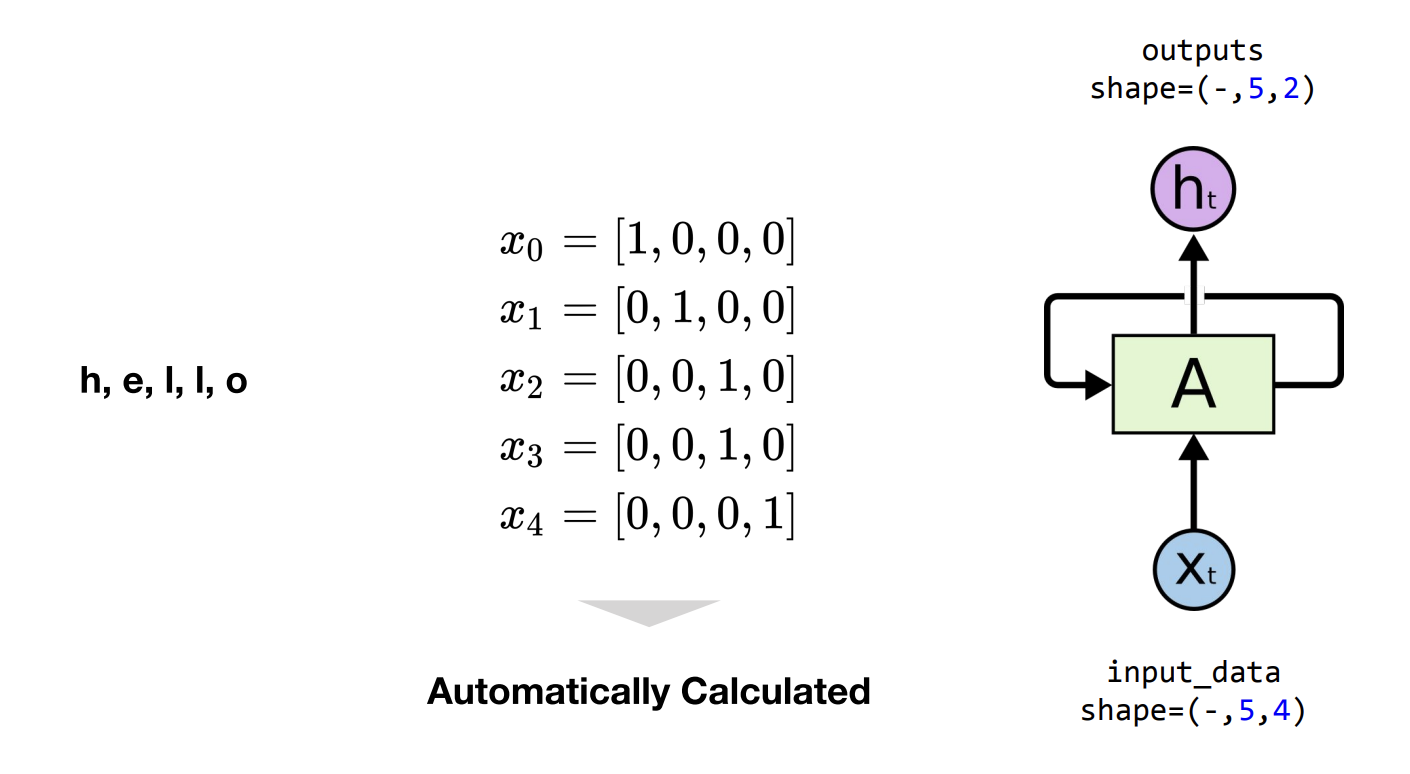
이번에는 input_data shape 의 중간성분에 대해서 알아보겠습니다.
위에서 사용되는 글씨의 개수와 글씨(단어)의 개수를 구분해서 설명을 드리고 있었습니다. 그 이유가 바로 이 sequence length 때문입니다.
중간 성분은 바로 단어자체의 개수라고 보시면 되겠습니다.
‘hello’ 라는 단어가 5개의 문자로 이루어져있으므로 중간성분은 5가 됩니다.
Batch Size
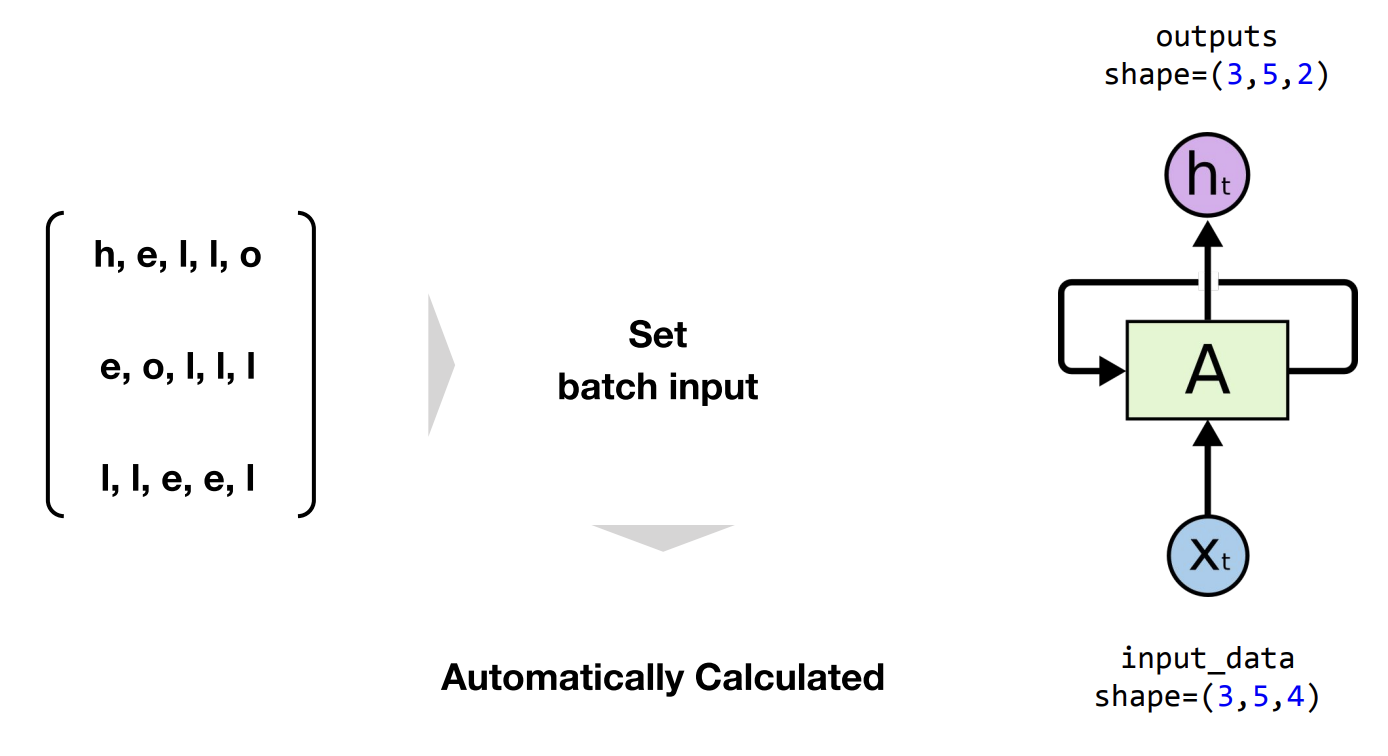
이전 글에서 미니배치관련 개념을 설명하면서 배치사이즈가 언급이 되었었습니다.
RNN에서도 마찬가지로 배치사이즈가 사용이되는데요, 그 이유는 문장을 학습한다고 가정했을 때, 단어 하나하나씩 매번 학습한다면 엄청나게 비효율적이 될 것이 뻔하기 때문에
배치사이즈라는 개념처럼 한번에 위 예시처럼 ‘hello, eolll, lleel’ 같이 세가지를 한번에 학습시키게 되는데 이 예시에서 볼 수 있듯이 3가지를 한번에 학습시킨다 = 배치사이즈가 3이다 로 이해하시면 될 것 같습니다.
그리고 코드 짤 때, 대박인점은
Pytorch에서는 Sequence Length 와 Batch Size를 굳이 입력해주지 않아도 알아서 완성시켜준다는 점. 입니다.
Output Shape
outputs shape 은 정말 간단합니다.
(ㅁ, ㅁ, -) 세가지 성분중 앞의 두가지 성분은 input shape 과 동일합니다.
(-, -, ㅁ) 그리고 세가지 성분중 맨 오른쪽 마지막 성분은 output size인데 이는 hidden size 와도 동일합니다.
이 output size(hidden size) 설정은 간단합니다. 그냥 본인 꼴리는대로 하고싶은대로 설정하시면 됩니다.
그렇다면 이 둘은 왜 같을까요?
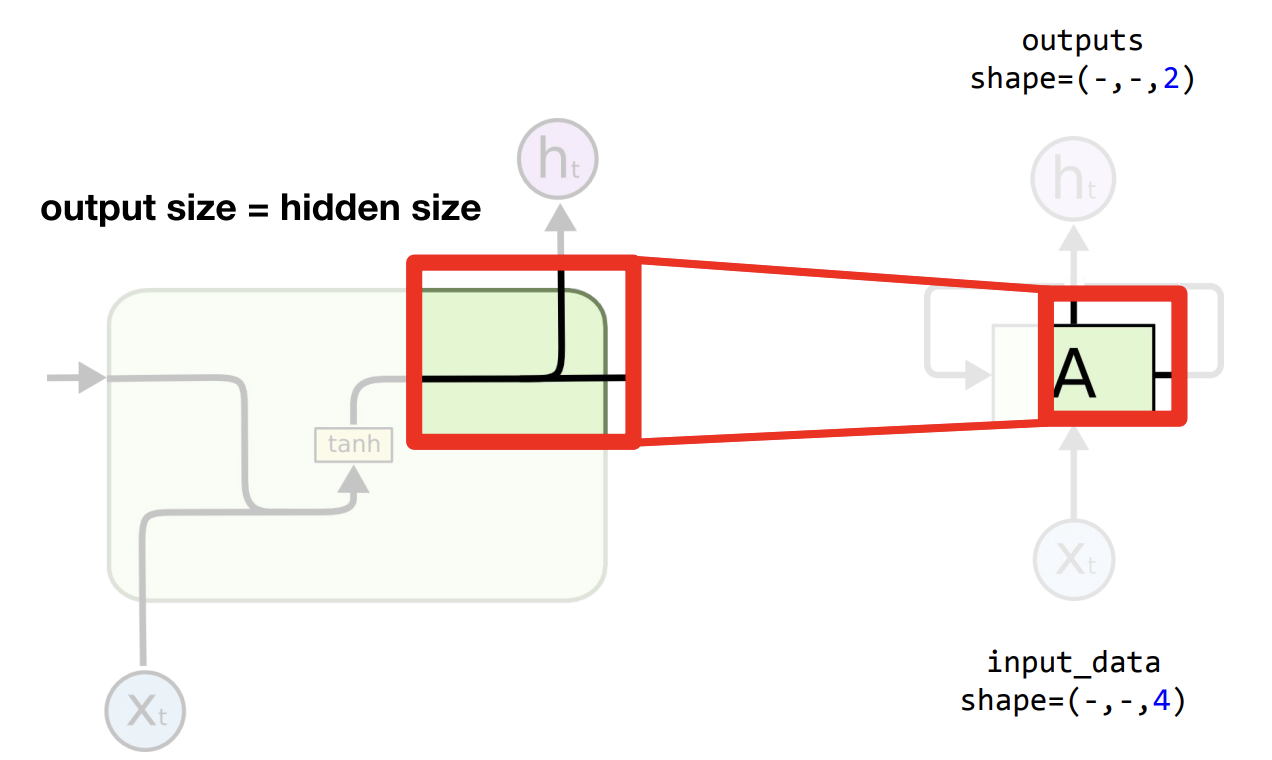
이렇게 셀 내부를 자세히 들여다보게되면, 같은 출력값이 두갈래로 나뉘는 것을 보실 수 있습니다. 그렇기 때문에 출력값과 hidden size 값이 같을 수 밖에 없는 이유입니다.
댓글남기기