
Lec 11-2 : RNN Hihello and Charseq
딥러닝 공부 26일차
‘hihello’ problem
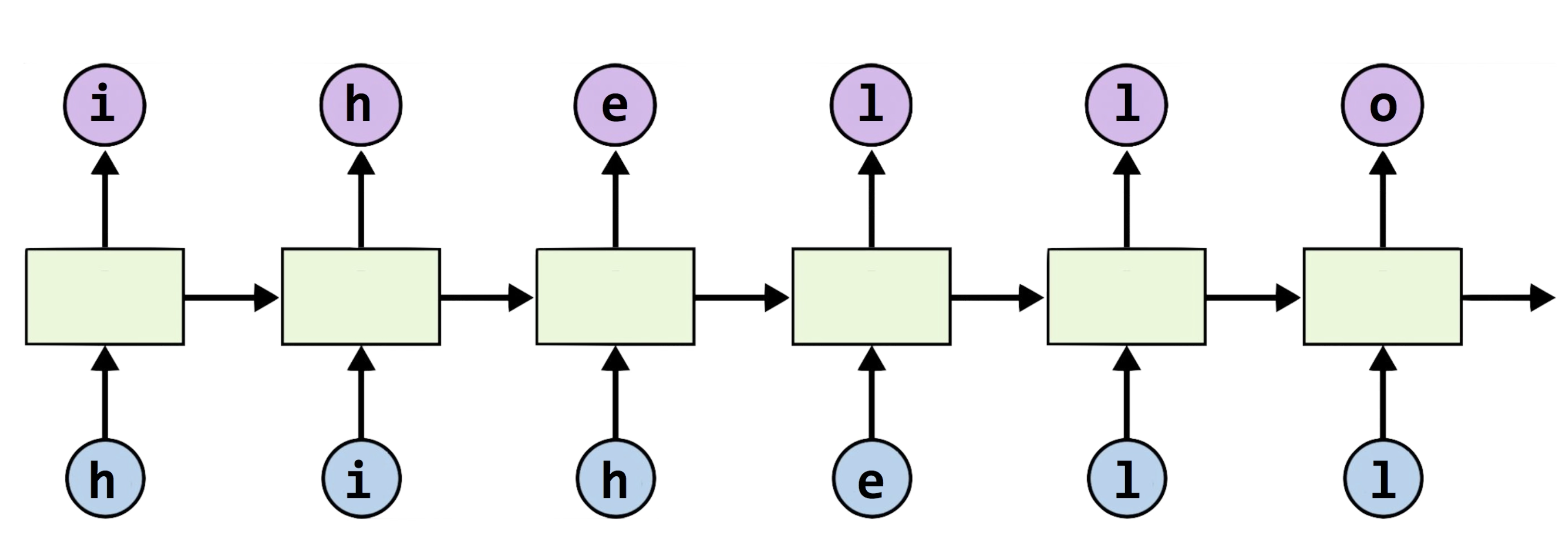
앞선 글에서는 hello라는 글자를 가지고 rnn을 돌리는 방법을 간략하게 알아봤었습니다.
이제는 그 글자가 hihello 로 바뀌었을 뿐인데요,
여기서 우리는 주목해야할 문제점이 있습니다.
h 같은 경우 그 다음 문자가 i 가 올지 e 가 오는지에 관해서 rnn을 구성해야한다는 점입니다.
문자 표현하기 by one-hot vector

문자를 만약에 위 그림의 왼쪽처럼 0,1,2,3,4 로 의미를 부여해준다고 한다면 컴퓨터의 입장에서는 o 가 h 보다 훨씬 중요한 문자구나 라고 인지하게 되는 오류가 발생할 수 있습니다.

그래서 원-핫 인코딩이 필요한 것입니다. 원-핫 벡터로 h, i ,e, l, o 를 표현하면 위 그림과 같습니다.
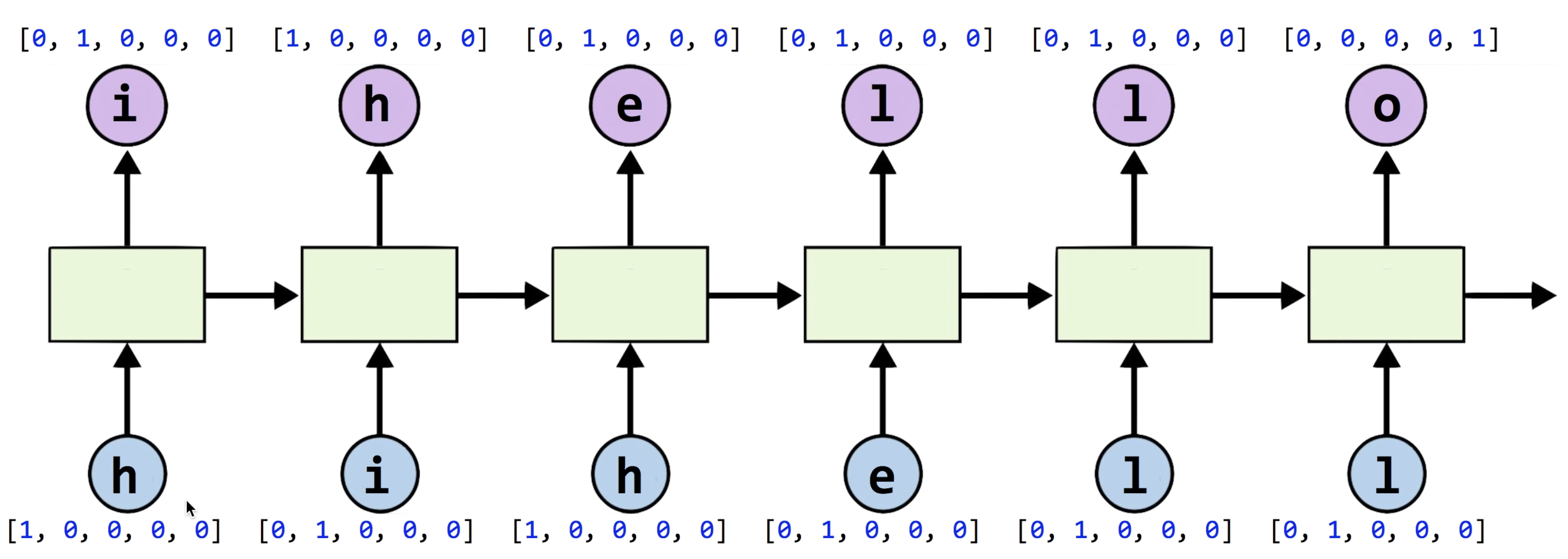
여기서 input_size는 사용되는 글자 수 즉, h,i,e,l,o 5개.
sequence length는 hihello니까 총 6개
batch_size는 한번에 한개의 글자씩 학습시키므로 1이 될 것입니다.
hidden_size(output_size)는 [-, -, -, -, -] 이렇게 5개가 있으므로 5라는 것을 아주 쉽게 알 수 있습니다.

우리의 목표는 hihell 까지 입력이 되었을때, ihello 가 출력되는 것이 목표임을 잊지 말아야합니다.
맨 윗줄의 char_set은 딕셔너리입니다. 그래서
h=0, i=1, e=2, l=3, o=4
로 할당되기 때문에, x_data는 입력값인 hihell 이므로 딕셔너리에 해당하는 값이 쓰여진 것이고
y_data는 출력값인 ihello 이므로 딕셔너리에 해당하는 값이 쓰여진 것입니다.
실제 구현까지는 진행하지 않고, hihello에 관한 데이터 준비 내용을 쭉 살펴보면
char_set = ['h', 'i', 'e', 'l', 'o']
#하이퍼 파라미터
input_size = len(char_set)
hidden_size = len(char_set)
learning_rate = 0.1
#데이터 세팅
x_data = [[0, 1, 0, 2, 3, 3]]
x_one_hot = [[[1, 0, 0, 0, 0],
[0, 1, 0 ,0, 0],
[1, 0, 0, 0, 0],
[0, 0, 1, 0, 0],
[0, 0, 0, 1, 0]]]
y_data = [[1, 0, 2, 3, 3, 4]]
#텐서변환
X = torch.FlotTensor(x_one_hot)
Y = torch.LongTensor(y_data)
Charseq
앞선 hihello 말고 이제는 어떠한 문장도 분석할 수 있게끔 하려고 합니다.

원하는 문장이 sample에 들어가게 되고, list(set(sample)) 을 하게 되면 sample에서 겹치는 글자를 제외한 리스트가 생성이 됩니다.
enumerate 함수를 이용하여 만들어진 char_set에 있는 글자를 하나씩 불러와서 딕셔너리로 만들어줍니다.
여기서도 마찬가지로 입력데이터는 맨 뒷글자를 제외하고 들어가야하기 때문에, [:-1] 처럼 슬라이싱을 하게되고
출력데이터도 맨 앞글자만 제외하고 나와야하므로 [1:]로 슬라이싱되는 것을 보실 수 있습니다.
이제 rnn을 직접 만들어보겠습니다. (기본 import는 생략하겠습니다.)
# RNN 선언
rnn = torch.nn.RNN(input_size, hidden_size, batch_first=True)
#batch_first 를 True로 해주면 우리가 배웠던 순서처럼 세팅이됩니다. (B, S, F)
# loss & optimizer setting
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.Adam(rnn.parameters(), learning_rate)
# 학습시작
for i in range(100):
optimizer.zero_grad()
outputs, _status = rnn(X)
# 입력값 x가 rnn을 돌고 나온 결과값이 outputs으로 저장되고 그리고 _status는 그 다음셀로 들어가야할 히든스테이트 값입니다. 이 두 값이 왜 같은지는 앞에서 설명했으므로 생략하겠습니다.
loss = criterion(outputs.view(-1, input_size), Y.view(-1))
loss.backward()
optimizer.step()
result = outputs.data.numpy().argmax(axis=2) #axix가 0이면 행을 기준으로 argmax 연산을 하고, 1이면 열을 기준으로 연산을 진행합니다. 여기서는 output data에서 axis=2 니까 세번째 성분인 hidden_size에 대해서 argmax를 진행합니다.
result_str = ''.join([char_set[c] for c in np.sqeeze(result)]) #스퀴즈함수를 이용해서, 차원이 1인 성분을 삭제해주니까 flatten 시켜주는 느낌으로 보시면 될 것 같습니다. 조금 더 알아봐야할 것 같습니다.
print(i, "loss: ", loss.item(), "prediction: ", result, "true Y: ", y_data, "prediction str: ", result_str)
다음 글에서는 시퀀스 투 시퀀스, 그리고 좀 더 긴 문장에 관해서 어떻게 학습하는지 배워보도록 하겠습니다.
끝!
참고 : 모두를 위한 딥러닝 시즌1
댓글남기기