
Lec 11-3 : RNN Long sequence
딥러닝 공부 27일차
Sequence dataset from long sentence

앞선 글에서는 문장을 커스터마이징 하는데까지 배워봤습니다.
그렇다면 위 그림과 같이 긴 문장은 어떻게 rnn으로 학습시킬 수 있을까요??
사실 현직에서 사용하는 정도의 긴 문장은 절대 아니지만 아직 배운 수준에 비해선 긴 문장이니 그냥 그런거로 하겠습니다.

x_data, y_data를 배열로 선언해줍니다.
반복문을 돌리는데, 우리는 긴 문장안에서 sequence_length 만큼씩 쪼개서 볼 겁니다.
예를들어 5개 글자중(공백포함) 시퀀스길이가 3이라면 5-3=2이므로 0부터2까지 3개의 반복문이 실행이 되는 것인데 이는 정확히 나눠서 세야할 반복 횟수와 동일합니다.
같은 원리로
for i in range(0, len(sentence) - sequence_length)
이렇게 표현이 되는 이유입니다.
긴 문장을 쪼개서 세주기 때문에 x_str에서 i번째 부터 i번째 + seqeunce_length 까지 슬라이싱해서 들어가게 됩니다.
마찬가지로 y는 예측값이자 출력값이므로 x보다 한글자씩 더 나아가야합니다. 그래서 +1이 붙습니다.
np.eye 함수로 원핫인코딩을 해줍니다. eye함수가 궁금하신 분들은 eye함수 알아보러가기 클릭해주세요
그리고 학습을 시켜야하므로 텐서로 변환해줍니다.
FC layer and stacking RNN
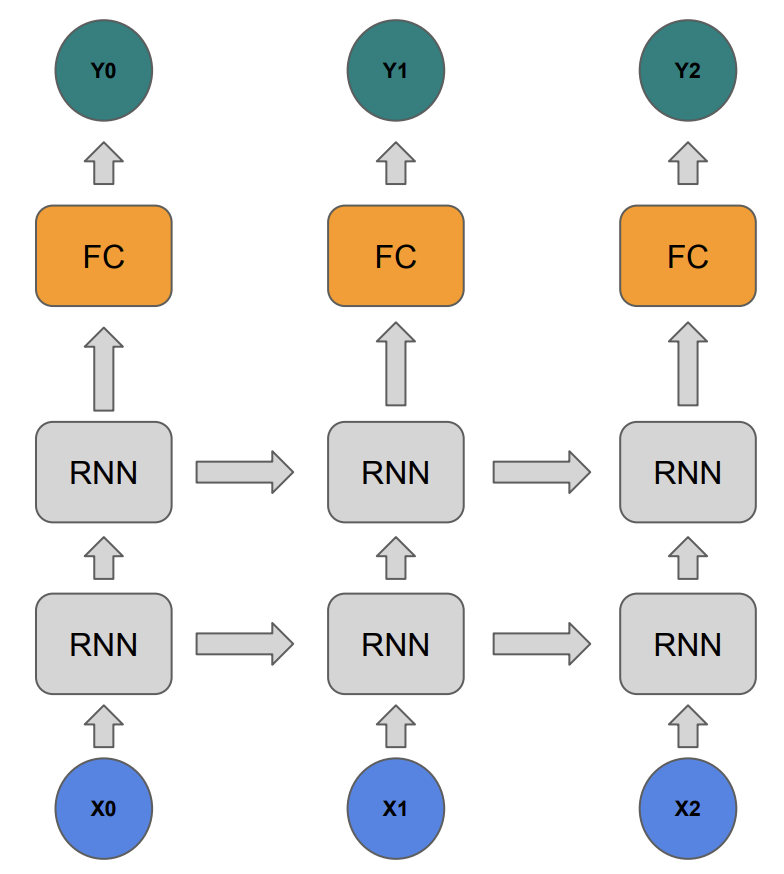
이제 RNN 모델을 쌓고 마지막에 FC layer 까지 추가해보도록 하겠습니다.
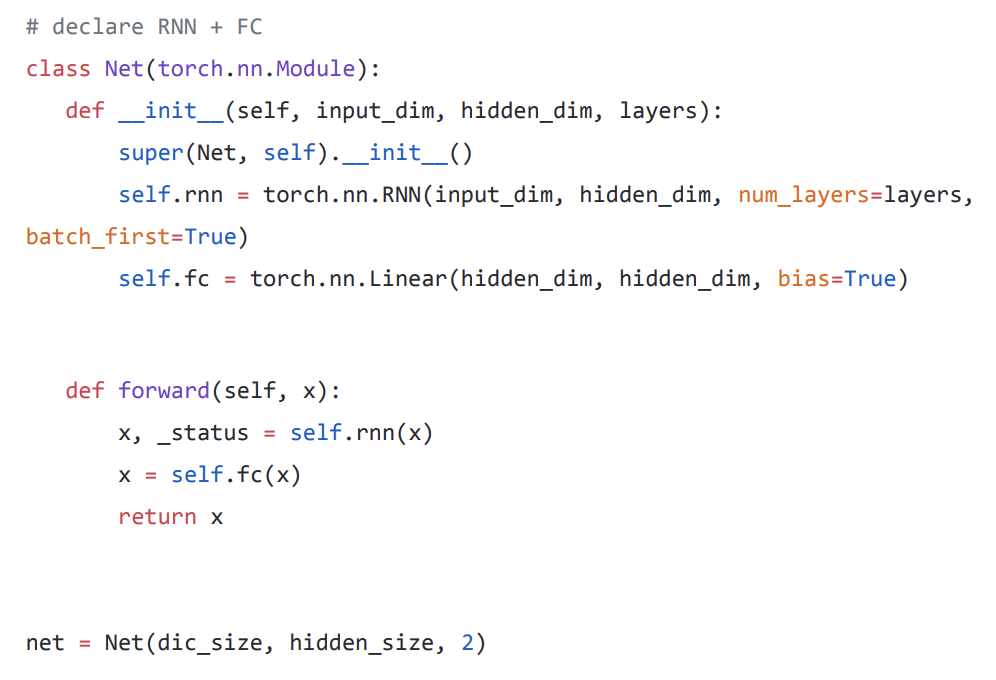
Net 이라는 상위 모듈에서 rnn 과 fc 하위 모듈을 가지게 됩니다.
그래서 forward 연산에서 rnn을 통과하고 나온 값이 fc layer를 거쳐서 return 되게 됩니다.
net = Net(dic_size, hidden_size, 2)
여기서 입력 사이즈 값과, 히든 사이즈 값은 정해줘야하는 값이므로 넣어주고, num_layers 값이 2가 되므로 RNN 층이 두개가 됩니다.
입력, 출력 값 중 sequence_length 와 batch_size는 pytorch에서 알아서 계산해주므로 신경 쓰지 않아도 됩니다.
Code run through

크로스엔트로피 손실함수를 사용하고, 옵티마이저로 아담을 사용합니다.
100번의 반복동안 그라디언트값은 초기화해주고 결과값 뽑고, 손실값 구하고, 역전파법하고, 손실함수 최저점을 구하러 한 단계 이동합니다.
여기까지는 그동안 많이 해서 익숙하네요
3차원 Argmax(dim=0,1,2)
이제 results = outputs.argmax(dim=2) 부터 하나씩 뜯어보겠습니다.
일단 argmax 에 관해서 조금 더 자세히 알아보겠습니다. 1,2 차원 배열의 argmax는 여기서복습 하고 오세요
3차원 배열의 argmax에서 dim에따라 어떻게 연산이 되는지 설명해드리겠습니다.
import torch
a3 = torch.FloatTensor([[[0.1, 0.3, 0.5],
[0.3, 0.5, 0.1]],
[[0.5, 0.1, 0.3],
[0.1, 0.3, 0.5]],
[[0.3, 0.5, 0.1],
[0.5, 0.1, 0.3]]])
print('argmax: ', a3.argmax(dim=0))
print('argmax: ', a3.argmax(dim=1))
print('argmax: ', a3.argmax(dim=2))
다음 결과 값을 출력해보면
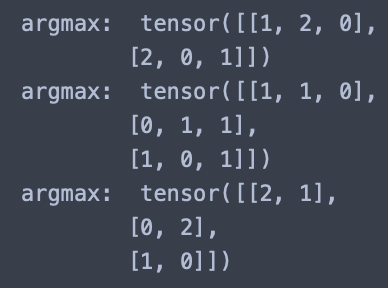
어떻게 이런 값이 나올 수 있을까요??
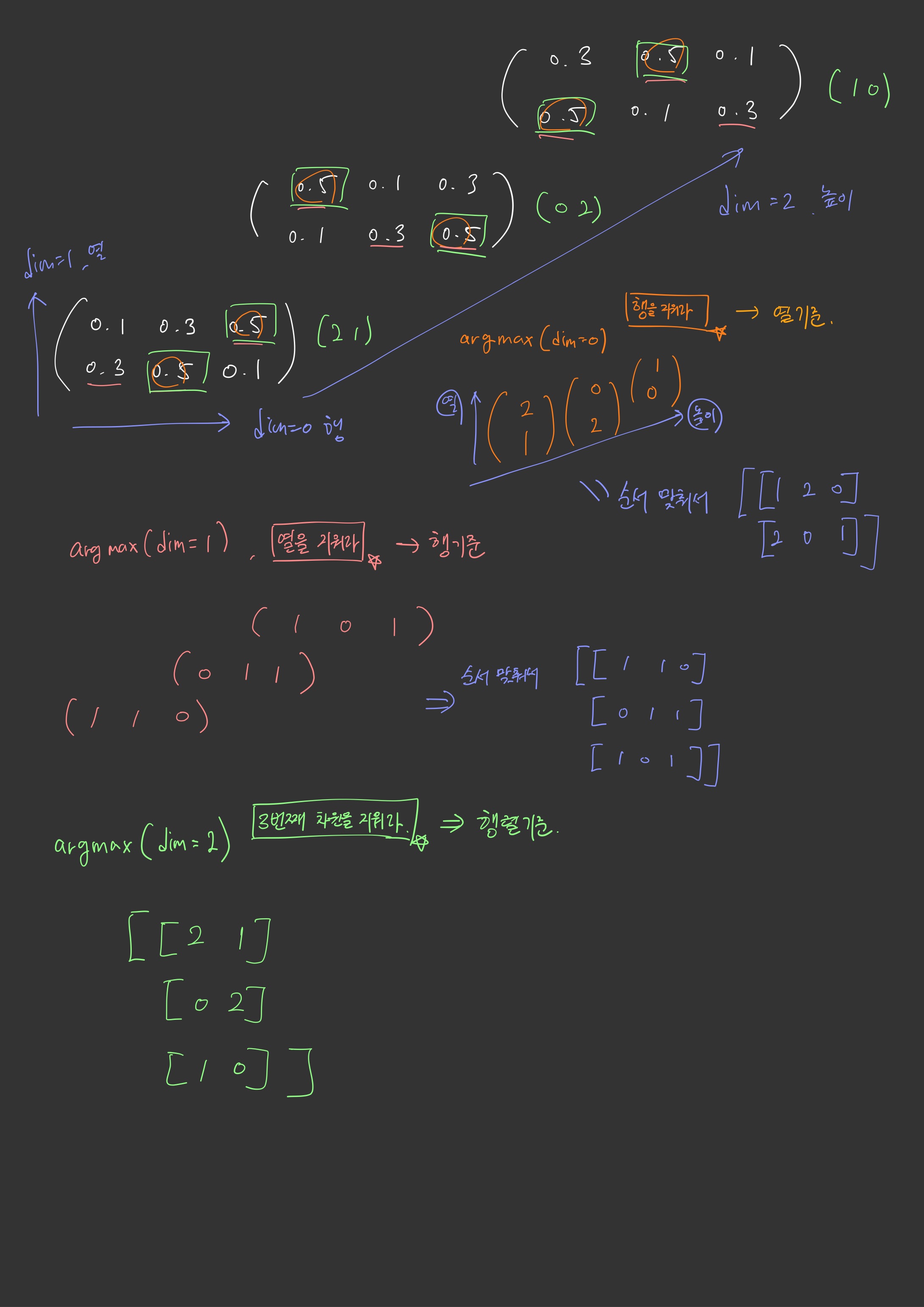
제가 직접 그려서 표현해봤는데 와 닿으실지는 모르겠습니다. 어쨋든 이어서 코드를 설명하면
results = outputs.argmax(dim=2) 에서 3번째 차원을 지우고, 즉 행렬의 기준으로 argmax연산을 취해주면 (batch_size, Sequence_length)의 행렬을 기준으로 남게됩니다.
output의 모양은 (sequence_length, batch_size, hidden_size) 입니다.
하지만 여기서 batch_first = True 를 해주면 순서가 (batch_size, sequence_length, hidden_size)로 바뀌게 됩니다.
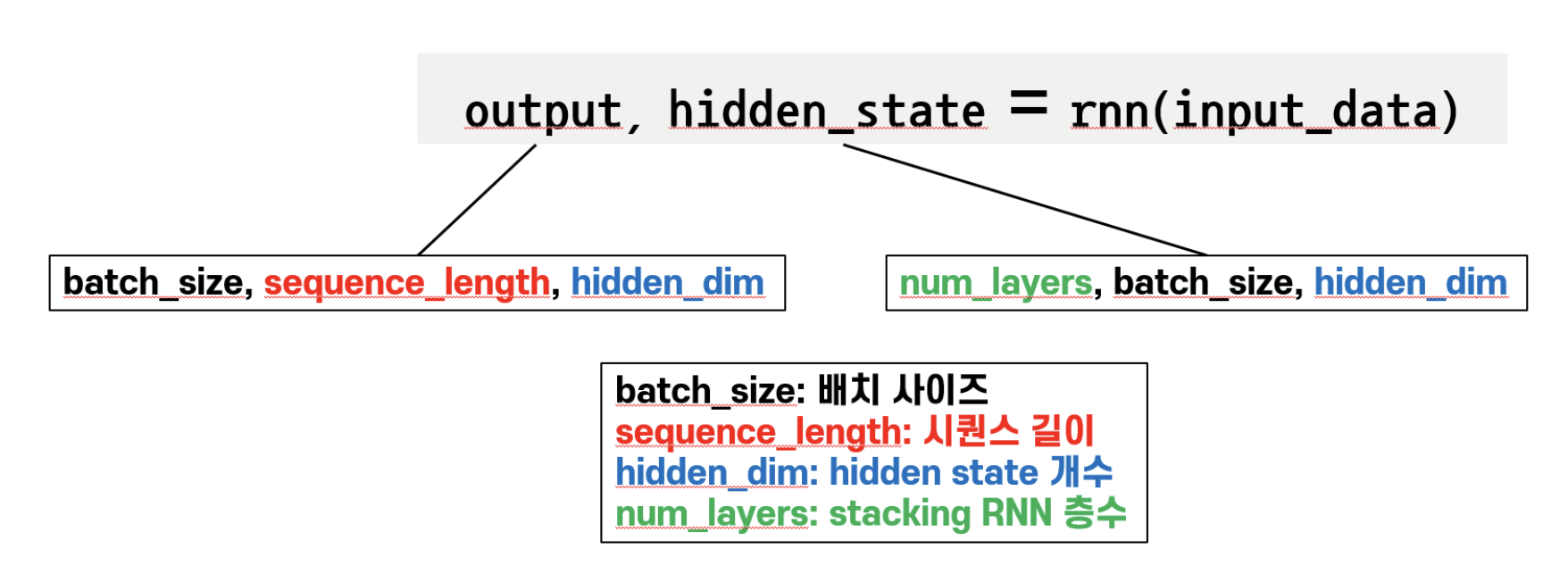
사진 참고하시면 좋을 것 같습니다. (출처:테디노트)
그렇게해서 j==0 일 때, 기존에 있던 맨 뒷글자를 제외한 나머지 글자들을 받아오게되고
else 에서 마지막 글자를 받아옴으로써, predict_str이 완성이 되게 됩니다.
댓글남기기