
Lec 11-4 : RNN Timeseries
딥러닝 공부 28일차
Time Series Data
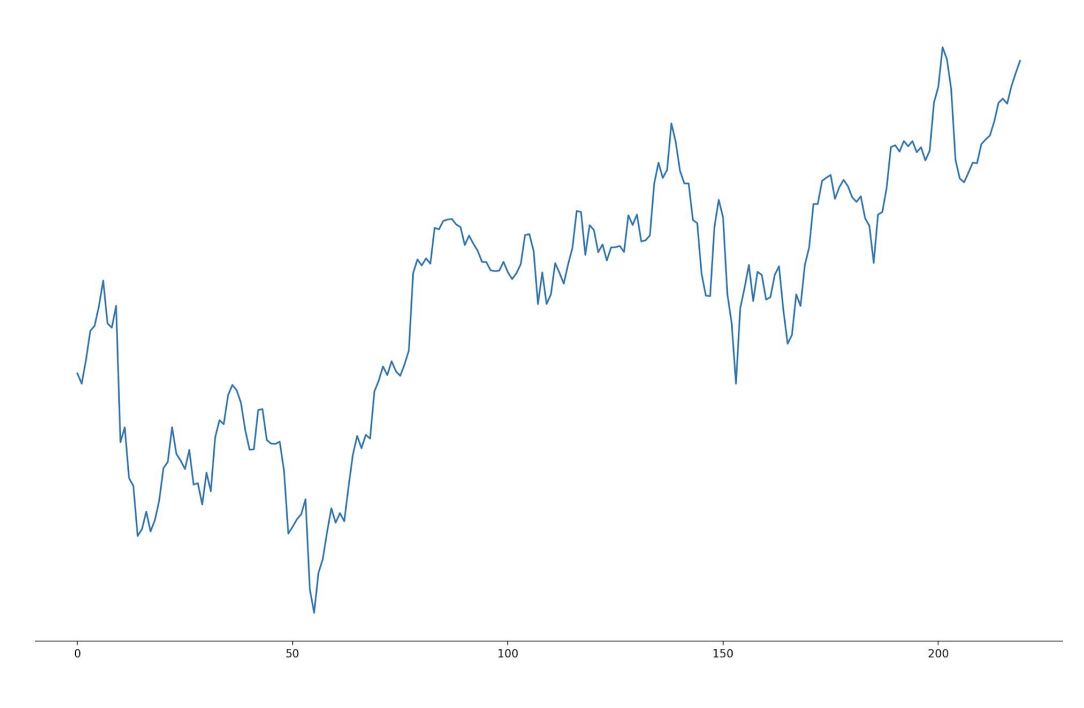
주식하는 사람들은 어디서 많이 본 그래프일 것 같은데요, 제가 봤을 때는 작년 미국시장 S&P500 지수 그래프와 많이 유사한 것처럼 보입니다.
각설하고, 이러한 주가는 여러가지 변수에 의한 요인이 있겠지만 어찌되었던 시간과 관련이 있는 데이터라고 할 수 있습니다.
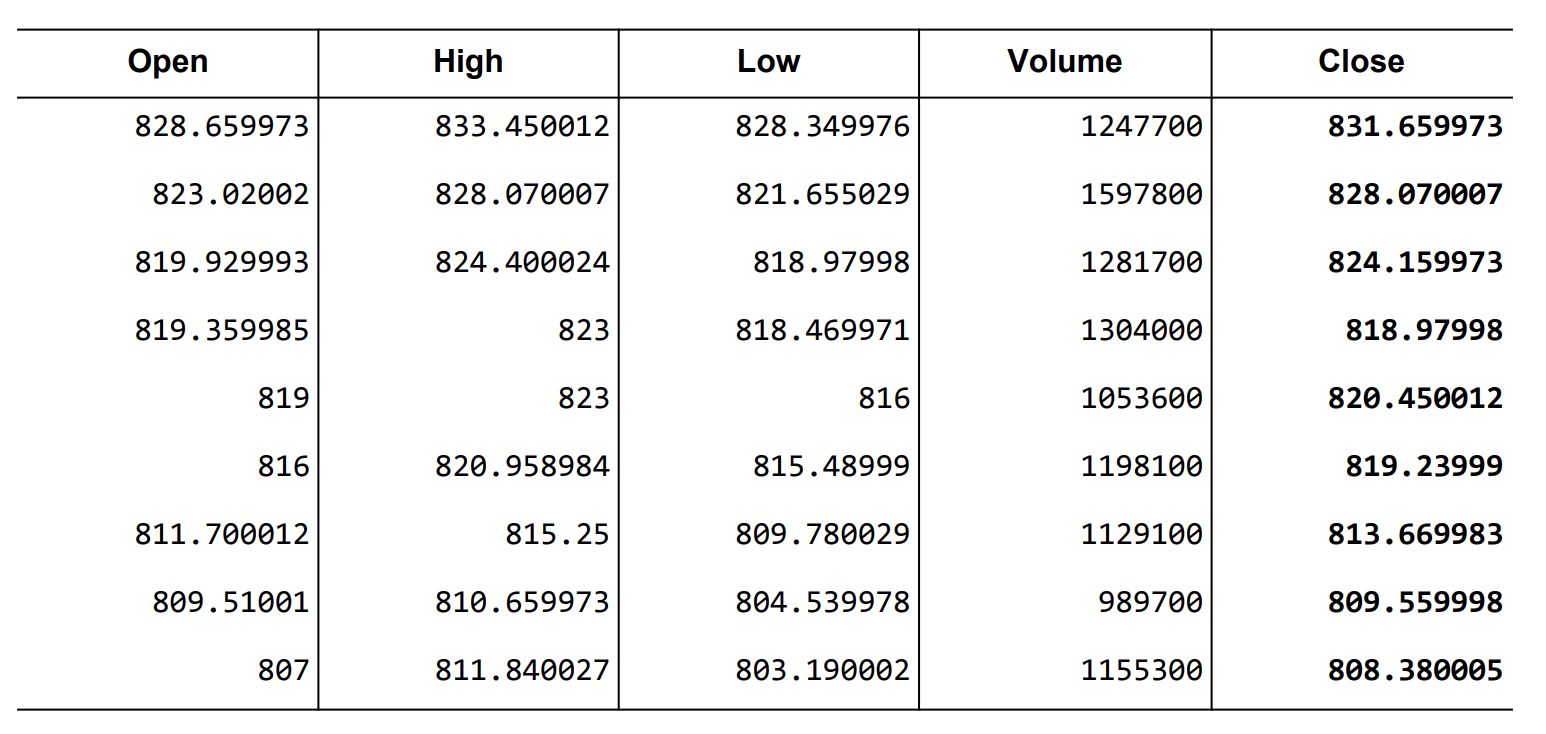
data-02-stock_daily.csv
이러한 주가에서 5가지 항목들을 예측해보는 모델을 만들어 보겠습니다.
5가지 항목은 시작가, 최고가, 최저가, 거래량, 종가 입니다.
Many-to-One
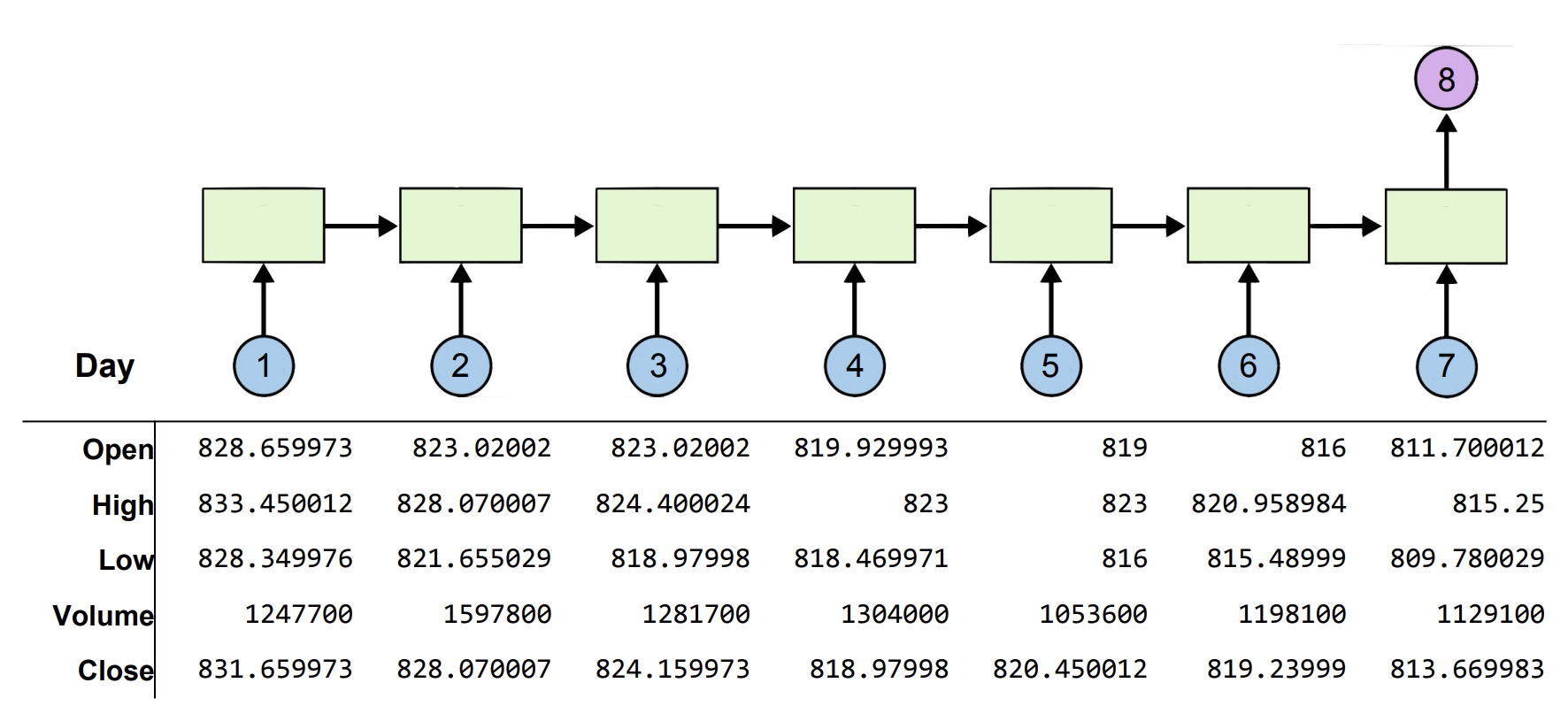
위 그림과 같은 구조를 여러개의 Input으로 한개의 결과값을 유추한다는 느낌으로 Many-to-One 이라고 표현합니다.
만약에 우리가 저 주가예측 RNN을 통해 종가를 알고 싶다고 가정해보겠습니다.
이 때, 마지막 8번으로 출력되는 값을 종가 한가지만 출력한다고하면 hidden_state = 1이 될 것입니다. 이렇게 되면 문제가 발생하는게 모델의 입장에서는 부담감이 확 커질 것 입니다.
왜냐하면 hidden_state 값이 한개가 되어버린다면 이전 셀들에서 나오는 모든 값들의 hidden_state 값이 1이 되어야 할 것입니다.
왜냐하면 output_size 와 hidden_size는 동일하기 때문입니다. 복습하고오기
그렇기 때문에 머신입장에서는 5가지의 성질로 학습한 것을 한가지의 결과물로 압축해서 표현해야하는데 이는 쉽지 않기 때문입니다.
그래서 보통적으로 한가지의 성질이 궁금하다면 hidden_size는 5라고 가정해보겠습니다. (5가지 성질을 보장할 만한 사이즈이기만 하면 됨)
그 hidden_size를 유지한채로 학습을 끝마친 뒤, FC layer를 통해 원하는 성질 값으로 뽑아내는 것이 일반적인 모델의 구성입니다.
Data Reading
# 기초 import setting
import torch
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
# 랜덤 시드
torch.manual_seed(0)
seq_length = 7 # 7일 간의 데이터로 학습한다고 했으므로
data_dim = 5 # 시가, 종가, 최고가, 최저가, 거래량 -> 5개
hidden_dim = 10 # 5개 이상의 널널한 값으로 그냥 10개라고 하겠습니다.
output_dim = 1 # FC layer를 거치고 뽑아낼 '종가' -> 1개
learning_rate = 0.01 # 학습률 = 0.01
iterations = 500 # Batch_size x iteration = 총 데이터 개수
xy = np.loadtxt("data-02-stock_daily.csv", delimiter=",") # 데이터 불러오기
xy = xy[::-1]
# 0부터10까지 배열이라하면 default 값은 [0:10:1]인데
# 마지막 1은 생략해서 썼던 것이고 여기서는 [::-1] 이라하면
# 처음부터 끝까지 다 세는데 -1 이므로 마지막에서 한개씩 세준다
# -> 거꾸로 뒤집는다.
# 역순으로 뒤집어주는 이유는 1일차부터 학습시키기 위한 것 같습니다.
train_size = int(len(xy) * 0.7) # 학습 사이즈로 데이터의 70%만 사용하겠다는 의미
train_set = xy[0:train_size]
test_set = xy[train_size - seq_length:]
+) csv 객체
text 파일 형태로 데이터 처리시 문장 내에 들어가 있는 콤마(,)에 대해 전처리 과정이 필요합니다. 따라서 CSV 객체를 사용하는 것이 한층 편리합니다. 파이썬에 내장되어 있습니다. (위 코드에서는 객체를 사용하지 않았습니다)
delimiter는 CSV 파일이 뭘로 나누어져 있는지(\t, ‘ ‘, ‘+’ 등)를 나타낸다.
train_set = minmax_scaler(train_set)
test_set = minmax_scaler(test_set)
# 스케일을 해주는 이유는 주가 같은 경우는 800정도의 숫자였고,
# 거래량 같은 경우에는 1,000,000 정도의 큰 숫자여서
# 기계 입장에서 각각 따로 학습하는 것이 부담이 되기 때문에,
# 둘다 0~1 사이의 값으로 정규화를 시켜주는 것이 좋습니다.
trainX, trainY = build_dataset(train_set, seq_length)
testX, testY = build_dataset(test_set, seq_length)
trainX_tensor = torch.FloatTensor(trainX)
trainY_tensor = torch.FloatTensor(trainY)
testX_tensor = torch.FloatTensor(testX)
testY_tensor = torch.FloatTensor(testY)
+) Minmax_scaler 함수
Minmax_scaler 함수는 스케일을 조정해주는 함수로, 모든 데이터가 0~1 사이의 값을 갖도록 해주는 함수입니다. (최대값은 1, 최소값은 0)
쉽게 말해서 정규화 함수라고 보시면 되겠습니다.
def minmax_scaler(data):
numerator = data - np.min(data, 0)
denominator = np.max(data, 0) - no.min(data, 0)
return numerator/(denominator + 1e-7)
def build_dataset(time_series, seq_length):
dataX = []
dataY = []
for i in range(0, len(time_series) - seq_length):
_x = time_series[i:i + seq_length, :]
_y = time_series[i + seq_length, [-1]]
print(_x, "->", _y)
dataX.append(_x)
dataY.append(_y)
return np.array(dataX), np.array(dataY)
minmax_scaler 와 build_dataset 코드입니다.
class Net(torch.nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim, layers):
super(Net, self).__init__()
self.rnn = torch.nn.LSTM(input_dim, hidden_dim, num_layers=layers, batch_first=True)
self.fc = torch.nn.Linear(hidden_dim, output_dim, bias=True)
def forward(self, x):
x, _status = self.rnn(x)
x = self.fc(x[:, -1]) #마지막 열, 직전 데이터
return x
net = Net(data_dim, hidden_dim, output_dim, 1) # 1층짜리 RNN
# loss & optimizer setting
criterion = torch.nn.MSELoss() #네트워크 출력값이 실수이기 때문에
optimizer = optim.Adam(net.parameters(), lr=learning_rate)
x[:, -1] 설명
배열 안에 , 가 있어서 도대체 무엇인가 했는데 , 기준 왼쪽이 행 오른쪽이 열의 의미입니다.
예시를 통해 빠르게 알아봅시다.
array[행 시작:행 끝, 열 시작:열 끝] array[2,:] - 행의 인덱스가 2인 값(3행) 추출. array[1:3,] - 행의 인덱스가 1,2인 값(2,3행) 추출. array[:,3] - 열의 인덱스가 3인 값(4열) 추출. array[:,:2] - 열의 인덱스가 2이하인 값(1,2열) 추출. array[3,2] - 행의 인덱스가 3, 열의 인덱스가 2인 값(4행3열) 추출. array[:2,1:3] - 행의 인덱스가 2이하, 열의 인덱스가 1초과3이하 인 값
Training & Evaluation
for i in range(iterations):
optimizer.zero_grad()
outputs = net(trainX_tensor)
loss = criterion(outputs, trainY_tensor)
loss.backward()
optimizer.step()
print(i, loss.item())
plt.plot(testY)
plt.plot(net(testX_tensor).data.numpy())
plt.legend(['original', 'prediction'])
plt.show()
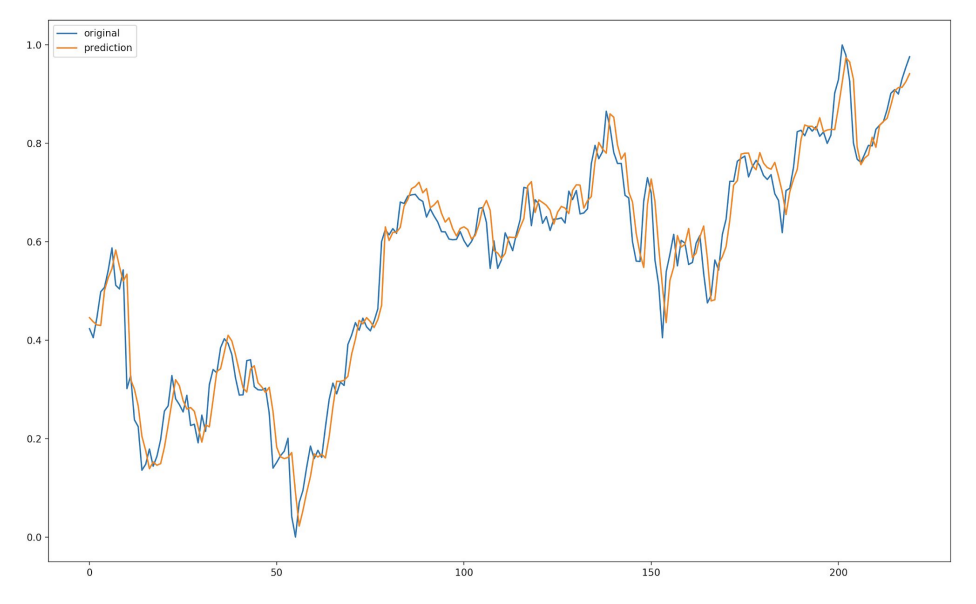
이렇게 간략하게 주식시장을 분석하는 법을 가볍게 다뤄보았습니다.
하지만 실제 주식시장은 정말로 너무나 다양한 변수들에 의해 가격이 결정되므로 실제 시장에서 이 모델을 사용했다가는 패가망신하기 딱 좋습니다 ㅋㅋㅋㅋㅋ
댓글남기기