
Lec 11-5 : RNN Seq2Seq
딥러닝 공부 29일차
Sequence to Sequence
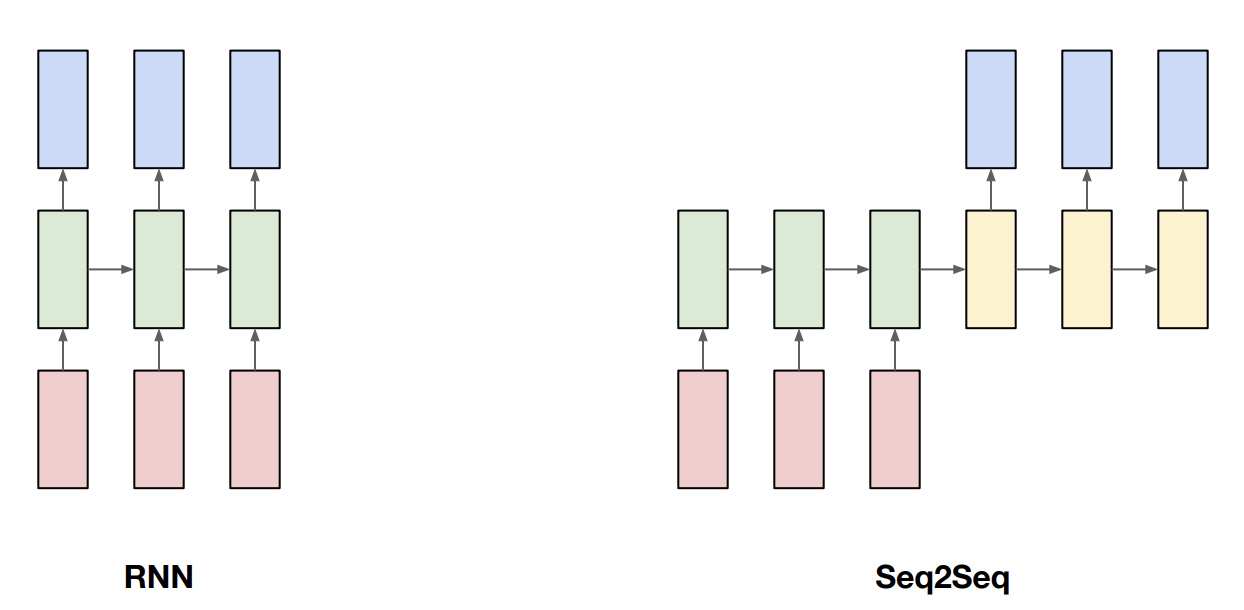
RNN은 sequencial data를 다루기 위해 만들어졌다고 하였었습니다.
기존의 rnn과 seq2seq는 무엇이 다른지 알아보겠습니다.
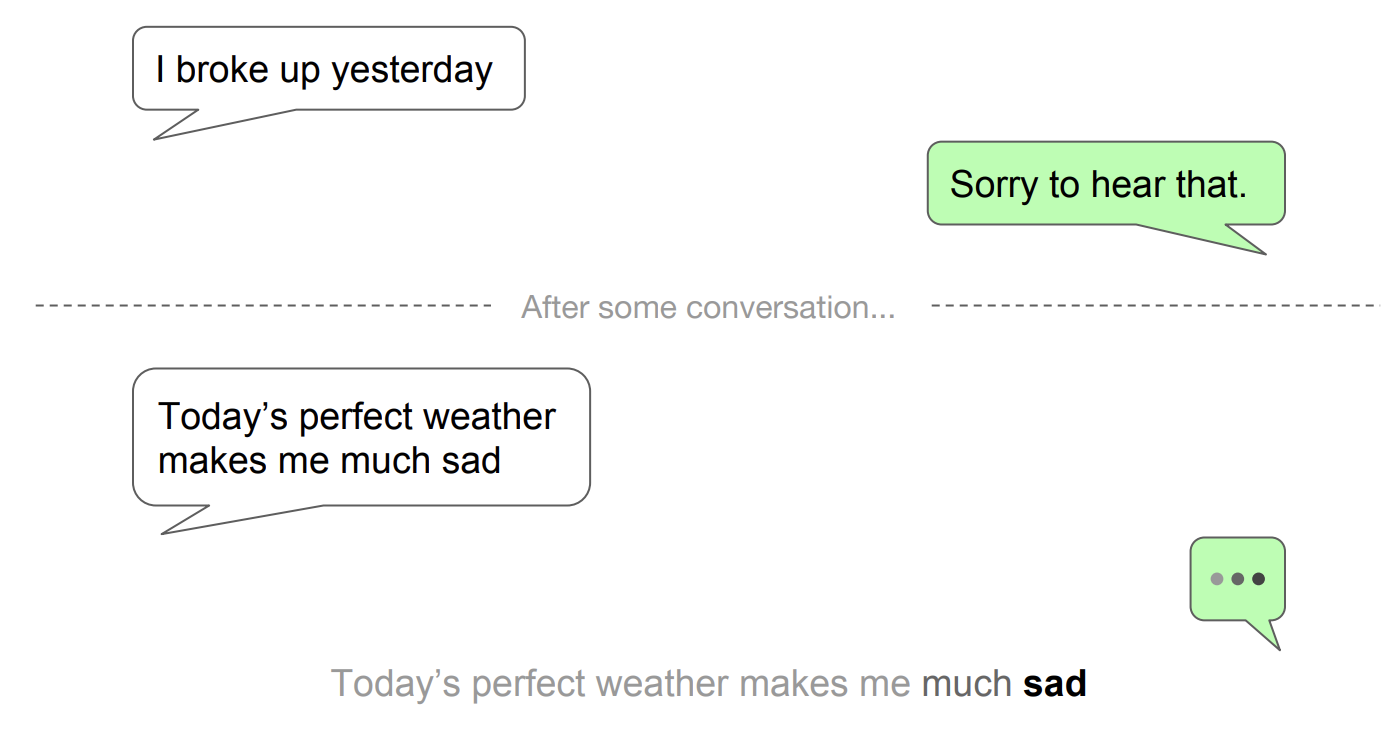
seq2seq 의 예시로 챗봇을 들 수 있습니다.
만약 기존의 rnn이였다면 “나 어제 헤어졌어” 를 듣고 “유감이다” 등의 위로까지는 잘 처리할 수 있어도
그 다음 대화가 진행되다가 “오늘 날씨가 너무 멋져서 나를 슬프게 해” 라고 했을 때 sad 전까지의 문장이 이미 rnn을 통해 학습해버리기 때문에, 날씨가 완벽해서 슬프다 라는 역설적인 맥락을 파악하지 못할 가능성이 높습니다.
이러한 문제점을 해결하기 위해 나타난 것이 Sequence to Sequence 입니다.
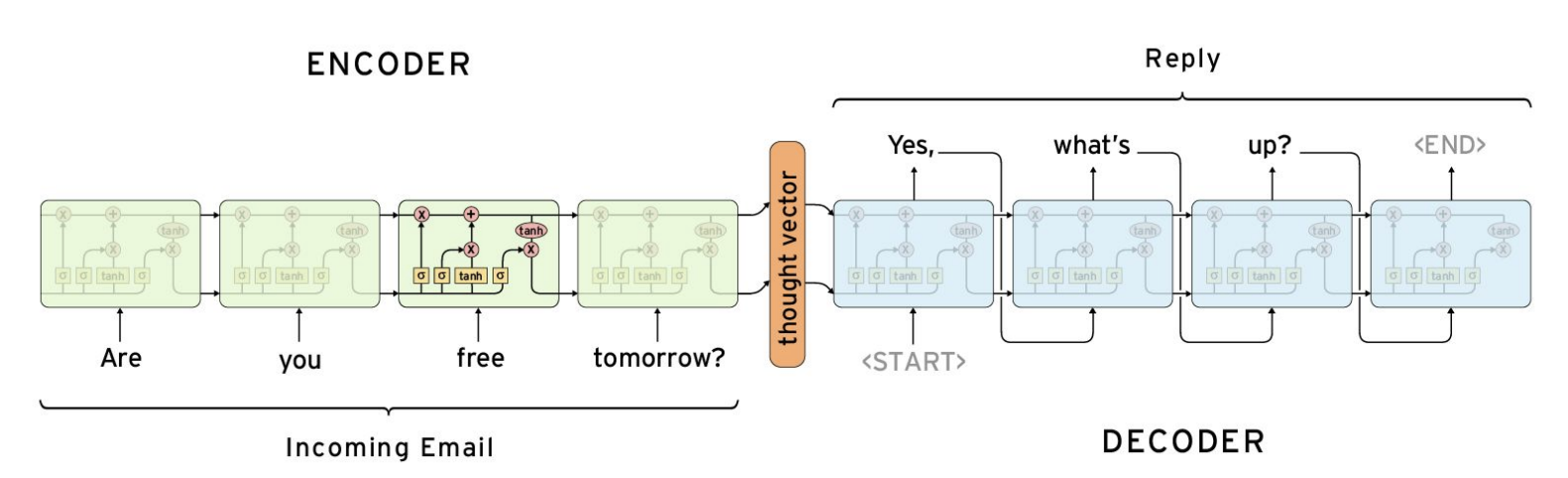
그래서 seq2seq 는 encoder 와 decoder 라는 크게 두 부분으로 나뉘게 되고, 앞선 예시를 예로 들면 “Today’s perfect weather makes me much sad” 라는 문장이 모두 encoder를 통해 입력이되고, 모두 입력이 되고난 다음에 decoder를 통해 전달하게 되는 방식입니다.
기존의 rnn에서 t -> o, o -> d … 이런식으로 한글자씩 바로바로 학습시킨다는 점과 차이점이 존재합니다.
Encoder-Decoder
아래는 전체적인 맥락을 파악할 수 있게 가져온 맨 앞줄의 코드와 맨 뒤쪽의 코드입니다.
import random
import torch
import torch.nn as nn
import torch.optim as optim
(...중략...)
# 아래는 번역을 수행하는 seq2seq 모델 구현 코드입니다.
SOURCE_MAX_LENGTH = 10 # 영어 문장
TARGET_MAX_LENGTH = 12 # 번역한 한국어 문장
load_pairs, load_source_vocab, load_target_vocab = preprocess(raw, SOURCE_MAX_LENGTH, TARGET_MAX_LENGTH)
print(random.choice(load_pairs))
# preprocess 보조함수 : 각각의 training,test set이 몇개의 단어로 되어있는지, 단어들은 무엇인지 찾아내는 과정
# 그리고 training set 과 test set을 나누는 과정
enc_hidden_size = 16
dec_hidden_size = enc_hidden_size
enc = Encoder(load_source_vocab.n_vocab, enc_hidden_size).to(device) #rnn layer
dec = Decoder(dec_hidden_size, load_target_vocab.n_vocab).to(device) #rnn layer
train(load_pairs, load_source_vocab, load_target_vocab, enc, dec, 5000, print_every=1000) # 학습 진행, encoder의 끝 부분이 decoder에 들어가는 것도 포함되어있을 것이다 예상 가능
evaluate(load_pairs, loa_source_vocab, load_target_vocab, enc, dec, TARGET_MAX_LENGTH)
이제 다시 처음부터 보겠습니다.
import random
import torch
import torch.nn as nn
import torch.optim as optim
torch.manual_seed(0)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
#예제니까 4줄 ><
raw = ["I feel hungry. 나는 배가 고프다.",
"Pytorch is very easy. 파이토치는 매우 쉽다."
"Pytorch is a framework for deep learning. 파이토치는 딥러닝을 위한 프레임워크이다."
"Pytorch is very clear to use. 파이토치는 사용하기 매우 직관적이다."]
SOS_token = 0 # Start of sentence
EOS_token = 1 # End of sentence
Data preprocessing
def preprocess(corpus, source_max_length, target_max_length):
print("reading corpus...")
pairs = []
for line in corpus:
pairs.append([s for s in line.strip().lower().split("\t")]) # Tab으로 스플릿 되어있는 부분은 나눠서
print("Read {} sentence pairs".format(len(pairs)))
pairs = [pair for pair in pairs if filter_pair(pair, source_max_length, target_max_length)]
print("Trimmed to {} sentence pairs".format(len(pairs)))
source_vocab = Vocab() #Vocab 은 클래스
target_vocab = Vocab()
print("Counting word...")
for pair in pairs:
source_vocab.add_vocab(pair[0])
target_vocab.add_vocab(pair[1])
print("source vocab size =", source_vocab.n_vocab)
print("target vocab size =", target_vocab.n_vocab)
return pairs, source_vocab, target_vocab
Neural Net Setting
class Encoder(nn.Module):
def __init__(self, input_size, hidden_size):
super(Encoder, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(input_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size)
def forward(self, x, hidden):
x = self.embedding(x).view(1, 1, -1)
x, hidden = self.gru(x, hidden)
return x, hidden
class Decoder(nn.Module):
def __init__(self, hidden_size, output_size):
super(Decoder, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(output_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size)
self.out = nn.Linear(hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, x, hidden):
x = self.embedding(x).view(1, 1, -1)
x, hidden = self.gru(x, hidden)
x = self.softmax(self.out(x[0]))
return x, hidden
여기서 나오는 encoder 와 decoder는 정말 기본적인 기능만 탑재된 class 입니다.
좀 더 나은 성능을 위해서는 나중에 attention 이라던지, 여러가지가 더 추가되게 됩니다.
Training
# Sentence 를 one-hot vector로 변환해주는 역할
def tensorize(vocab, sentence):
indexes = [vocab.vocab2index[word] for word in sentence.split(" ")]
indexes.append(vocab.vocab2index["<EOS>"])
return torch.Tensor(indexes).long().to(device).view(-1, 1)
def train(pairs, source_vocab, target_vocab, encoder, decoder, n_iter, print_every=1000, learning_rate=0.01):
loss_total = 0
encoder_optimizer = optim.SGD(encoder.parameters(), lr=learning_rate)
decoder_optimizer = optim.SGD(decoder.parameters(), lr=learning_rate)
training_batch = [random.choice(pairs) for _ in range(n_iter)]
training_source = [tensorize(source_vocab, pair[0]) for pair in training_batch]
training_target = [tensorize(target_vocab, pair[1]) for pair in training_batch]
criterion = nn.NLLLoss() # negative log likelyhood loss function (카테고리 value 비교할 때 많이 사용)
def train(pairs, source_vocab, target_vocab, encoder, decoder, n_iter, print_every=1000, learning_rate=0.01):
for i in range(1, n_iter + 1):
source_tensor = training_source[i - 1]
target_tensor = training_target[i - 1]
encoder_hidden = torch.zeros([1, 1, encoder.hidden_size]).to(device) # 첫번째 GRU cell 에 들어가는 hidden = 0
encoder_optimizer.zero_grad()
decoder_optimizer.zero_grad()
source_length = source_tensor.size(0)
target_length = target_tensor.size(0)
loss = 0
for enc_input in range(source_length):
_, encoder_hidden = encoder(source_tensor[enc_input], encoder_hidden) #encoder 마지막 hidden state, decoder에 들어갈 준비
def train(pairs, source_vocab, target_vocab, encoder, decoder, n_iter, print_every=1000, learning_rate=0.01):
decoder_input = torch.Tensor([[SOS_token]]).long().to(device)
decoder_hidden = encoder_hidden
for di in range(target_length):
decoder_output, decoder_hidden = decoder(decoder_input, decoder_hidden)
loss += criterion(decoder_output, target_tensor[di])
decoder_input = target_tensor[di] # teacher forcing
loss.backward()
encoder_optimizer.step()
decoder_optimizer.step()
loss_iter = loss.item() / target_length
loss_total += loss_iter
if i % print_every == 0:
loss_avg = loss_total / print_every
loss_total = 0
print("[{} - {}%] loss = {:05.4f}".format(i, i / n_iter * 100, loss_avg))
이상 여기까지 seq2seq 코드였습니다.
댓글남기기