
Lec 11-6 : RNN Packed Sequence
딥러닝 공부 30일차
Sequential Data
이번에는 길이가 각각 다른 시퀀스 데이터를 하나의 배치로 묶는 2가지 방법에 대해서 알아보겠습니다.
자세히 알아보기 전에 sequential data 가 또 무엇이 있는지 알아보겠습니다.
시퀀셜 데이터는 길이가 정해지지 않는 경우가 많습니다.
Padding
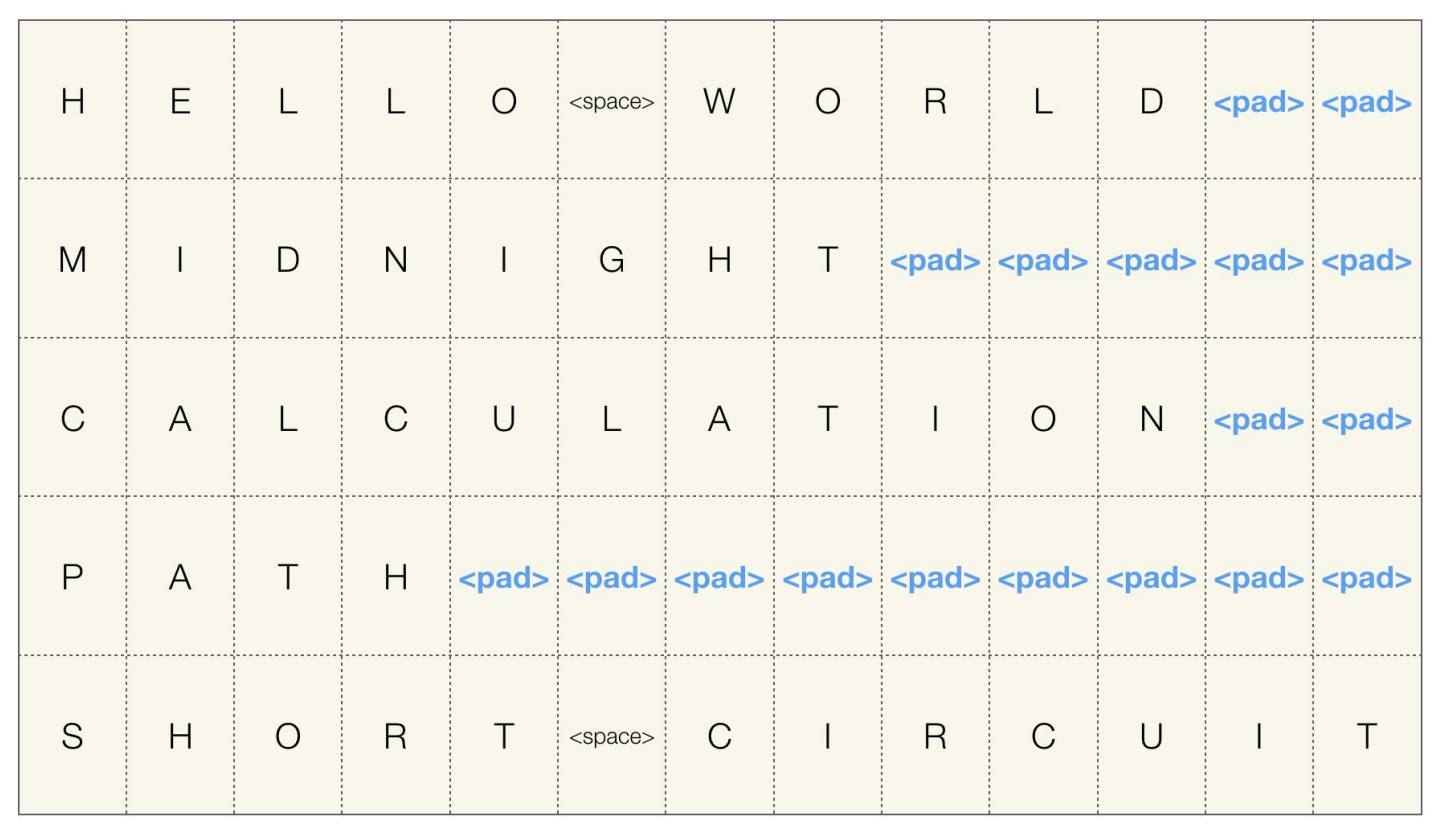
CNN을 공부할 때 배웠던 padding과 비슷한 느낌입니다.
위 그림과 같이 다섯개의 각기 다른 사이즈를 가진 시퀀셜 데이터를 하나의 배치로 묶으려면 $\text{
패딩의 장점은 데이터가 깔끔하게 정리되어서 컴퓨터에서 처리하기 간편해진다는 점 입니다.
단점은 이렇게 빈 공간들을 패딩으로 채워넣기 때문에, 안해도 될 연산들을 해주어야 한다는 점도 존재합니다.
Packing
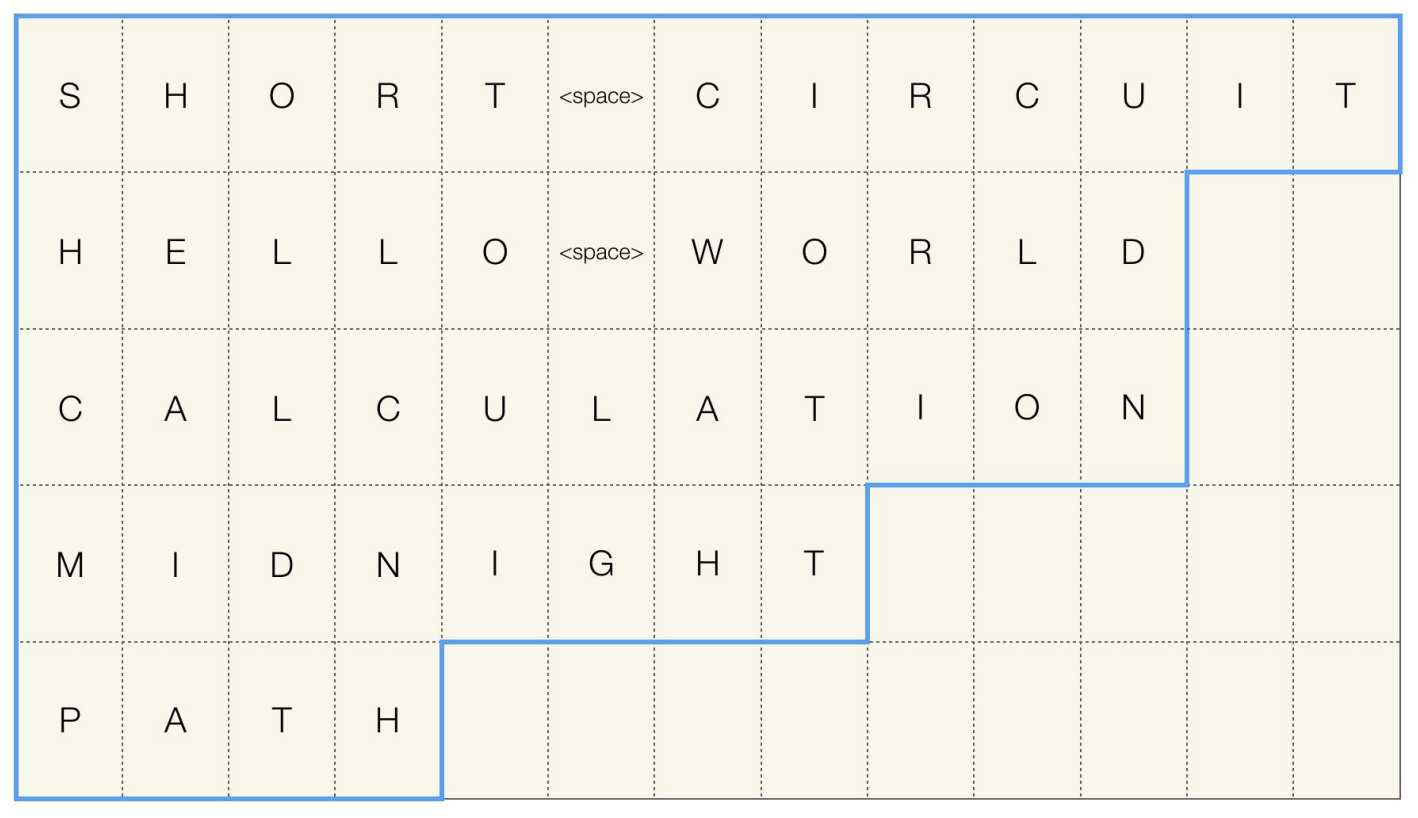
두번째 방법인 패킹은 시퀀스 길이에 대한 정보를 저장하고 있는 방식으로 진행됩니다.
하지만 이 방법이 pytorch에서 동작하려면 길이 내림차순으로 정렬 되어야 합니다.
이를 사용하면 패딩보다는 효율적으로 계산할 수 있는 장점이 있고,
내림차순으로 정렬해야하고, 패딩보다는 조금 복잡하다는 단점이 있습니다.
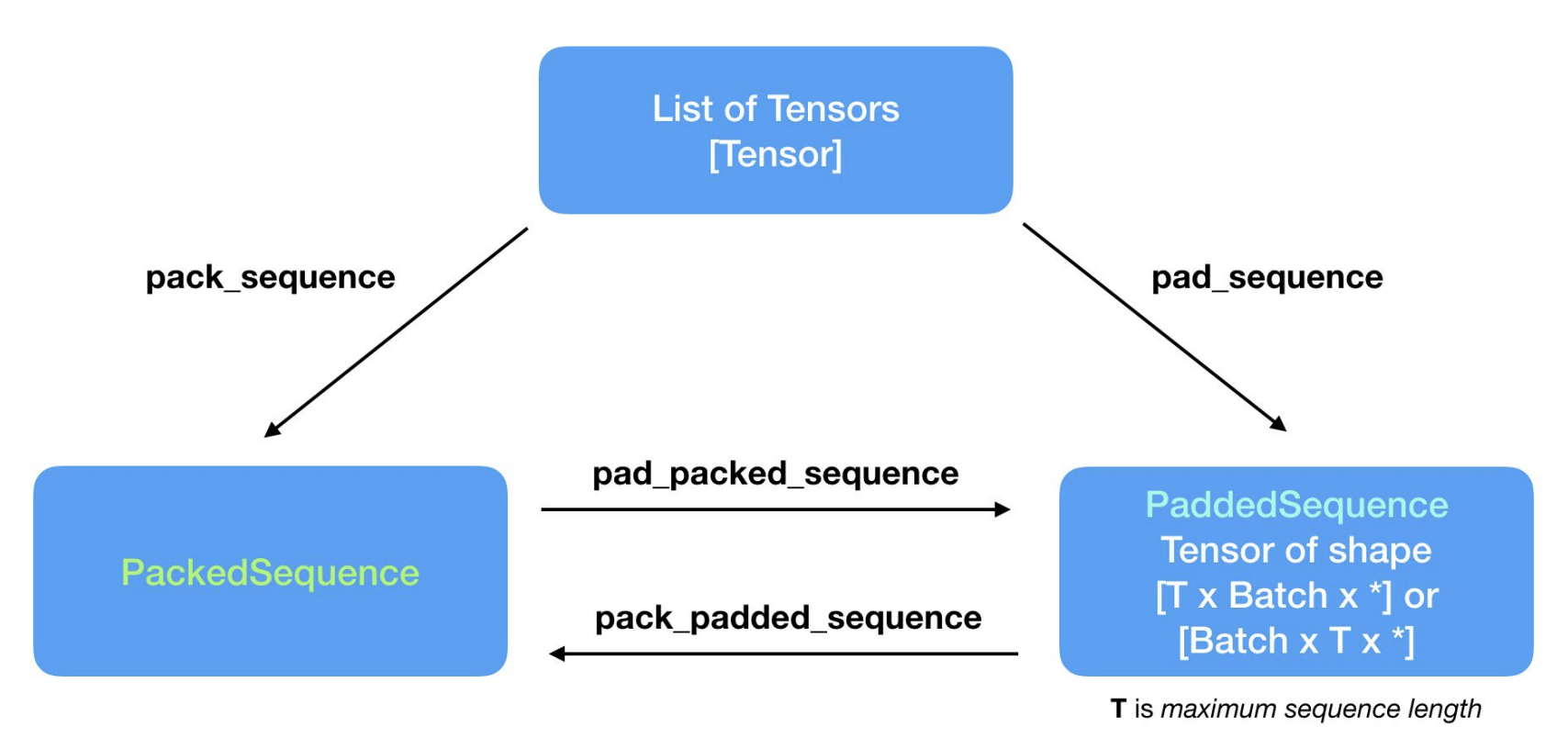
패딩과 패킹 사이의 관계도 입니다.
댓글남기기