
Attention is all you need(NIPS) : Transformer
Transformer
참고문헌 <-여기서 정말 많이 퍼왔음을 알립니다.
오늘은 Google에서 발표한 논문 Attention is all you need(NIPS)에서 소개한 모델 Transformer에 대해서 알아보겠습니다.
Seq2seq Machine Translation
Transformer 이전의 seq2seq ahepfdms RNN 또는 CNN 을 이용하여 sequential data를 처리했습니다.
seq2seq 모델의 단점은 아래와 같습니다.
1) 상당한 계산복잡도
2) RNN에서 layer 내에서 병렬처리 불가
3) long-range-dependency를 가진 정보를 참조하는 경우 긴 path를 거쳐 전달된다
RNN

위 gif는 RNN으로 영어 문장 "The dog likes sausage" 을 한글로 번역하는 예시입니다.
이 문장을 RNN을 통해 번역하면, “강아지가 소시지를” 까지 번역했을 때, “먹는다”, “좋아한다” 등의 단어들이 높은 확률로 예측됩니다.
하지만 번역을 해야하므로 원문의 “like” 의미를 반영해야합니다.
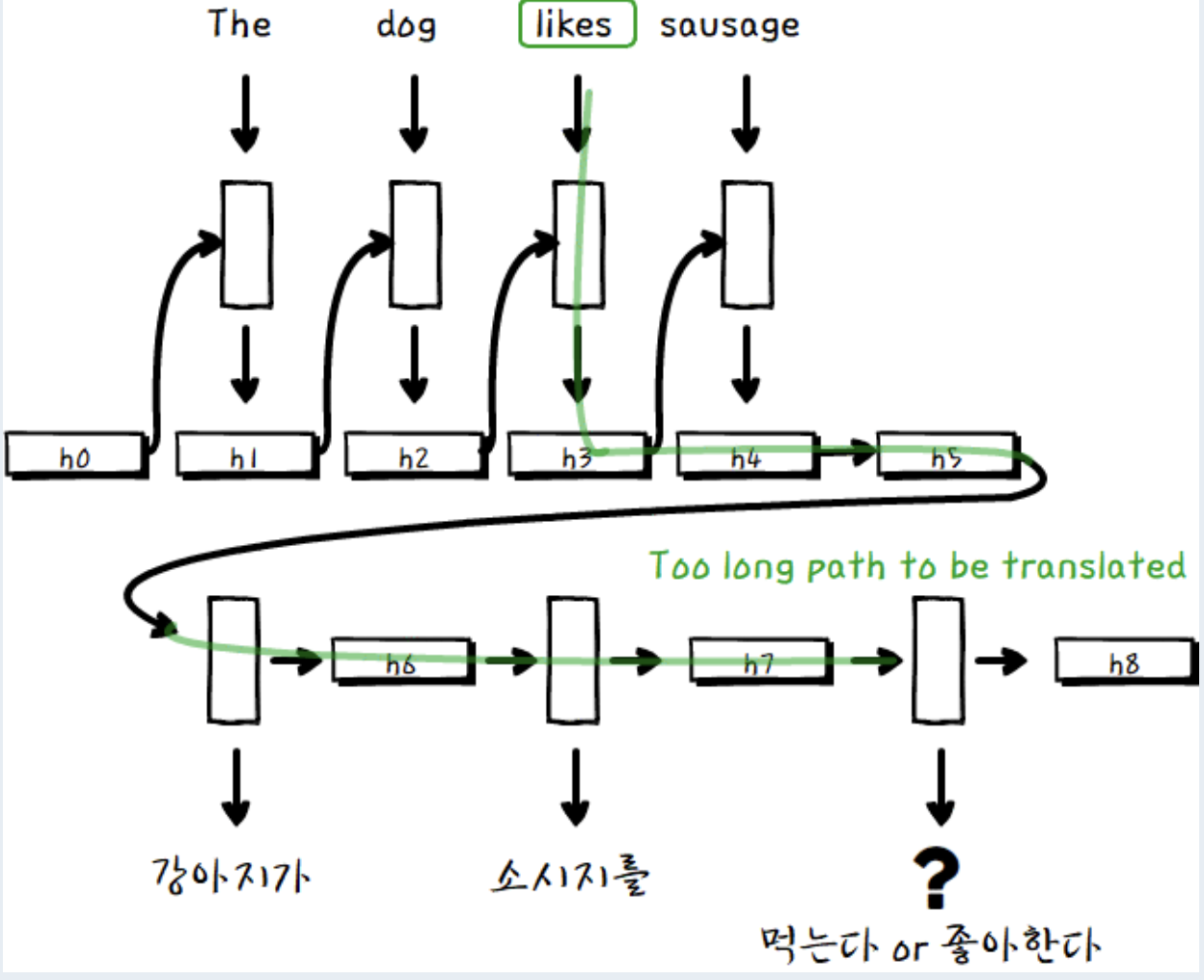
하지만 위 사진에서 볼 수 있듯이, like는 여러 hidden layer를 거치며, 그 정보가 희석됐을 확률이 높습니다.
RNN with attention
이러한 RNN의 단점을 극복하기 위해 제안된 모델이 Attention을 사용하는 모델입니다.
Attention
attention 은 주로 자연어 처리에 사용되는데, attention은 해당 시점에서 예측해야할 단어와 관련있는 입력 단어(Input word)를 중점적으로 본다고 할 수 있습니다.
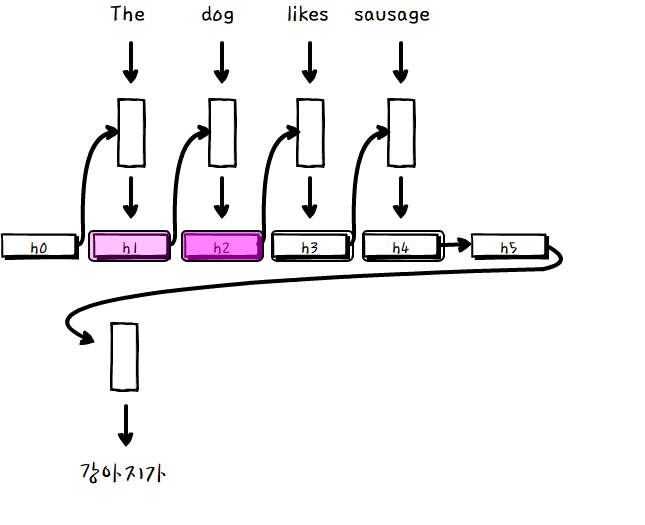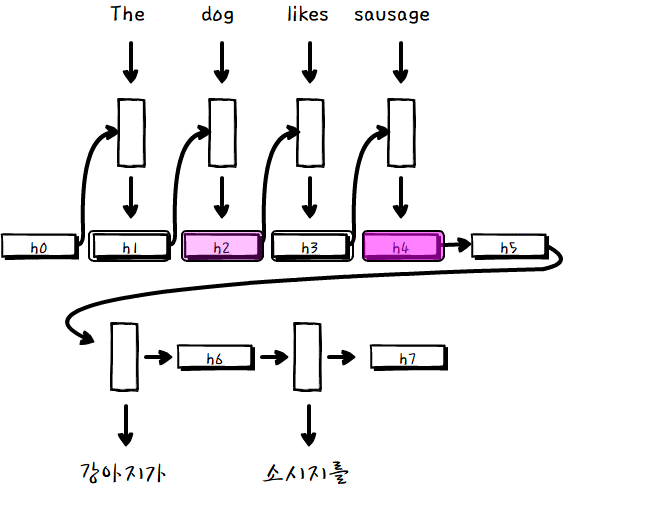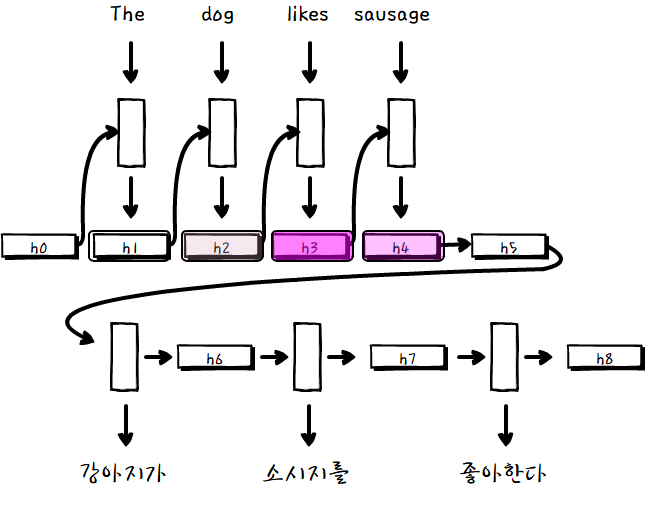
input sentence 각각의 단어에 해당하는 hidden layer와 당장 출력해야하는 단어의 연관성을 기반으로 모든 셀을 거치는 것이 아닌, 선택과 집중을 한다고 생각하면 될 것 같습니다.
관련도가 높은 source 단어에 더 가중치를 두어서 output을 계산합니다.
하지만 안그래도 layer내에서 병렬처리가 불가능해서 계산 복잡도가 높은 RNN에서 Attention 까지 추가가 되면 그 복잡도는 어마무시하게 됩니다.
여기서 논문 저자들이 제기한 의문이
만약 attention을 통해 참조해야할 source의 위치를 알 수 있다면, 굳이 sequence를 고려할 필요가 있나?? 라는 점입니다.
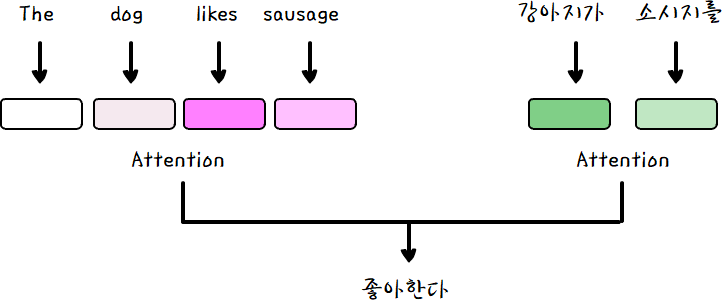
위 이미지와 같이 오직 input과 이전 output 값들의 attention만을 이용하여 다음 단어를 출력하여 계산 복잡도를 축소할 수는 없을까? 라는 것이 핵심입니다.
Self-attention
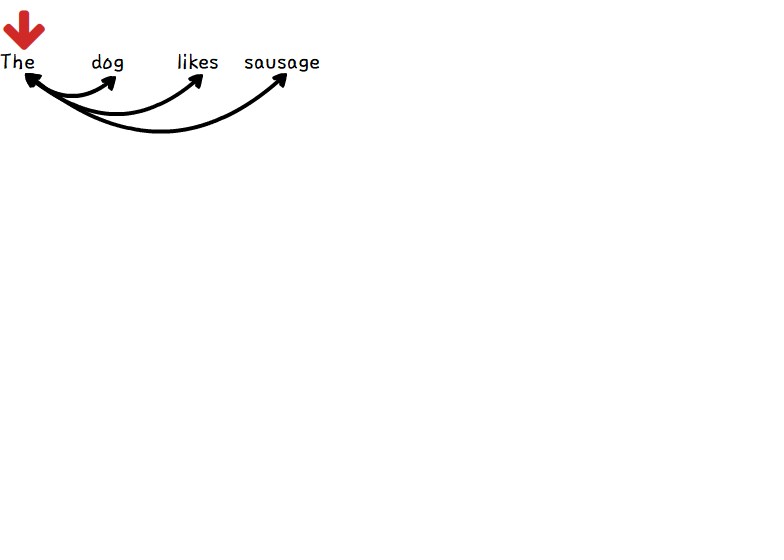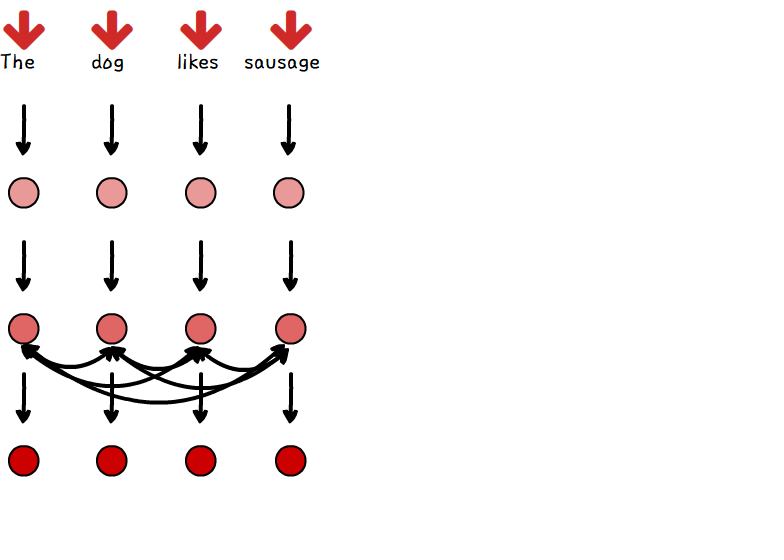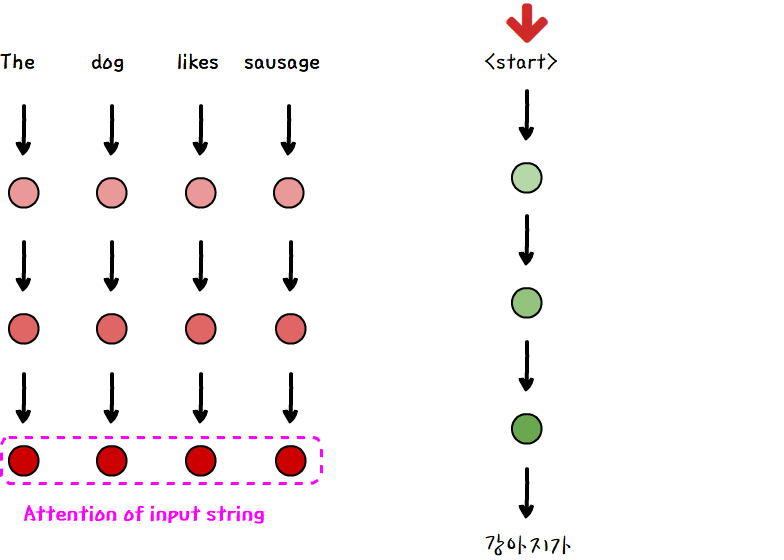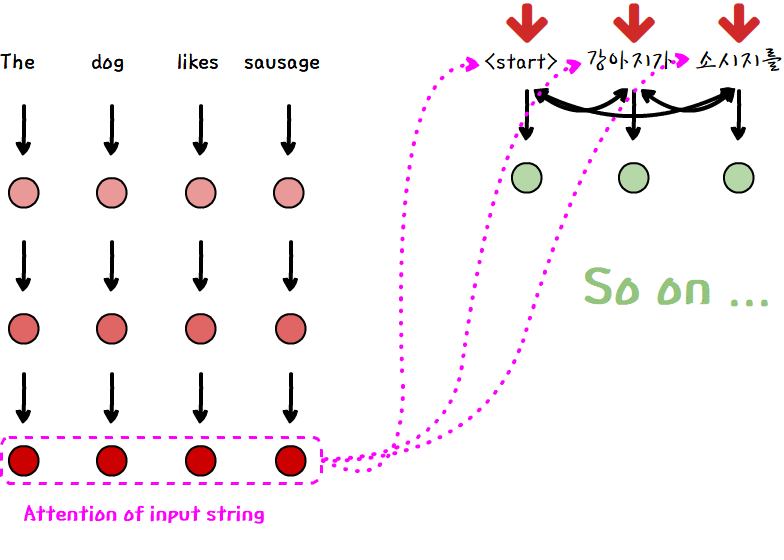
기존 attention 모델이 output을 출력할 때만, attention을 이용했다면, Transformer는 sequence 내에서 단어 간의 관계 정보를 self-attention을 이용해 미리 계산합니다.
댓글남기기