
Voice Recognition - 딥러닝 기초 01
Tacdemy_1강
딥러닝 기초 1강
사진 자료들은 티아카데미, 도승현 강사님의 ppt에서 따왔음을 알립니다.
- 딥러닝 기초 리뷰
- FC Layer, CNN, RNN, LSTM, Attention
- Audio Classification & Tagging
- 데이터 파이프라인의 이해
- CTC
- 논문 및 이해, CTC Loss 쓰는 법
- Deep Speech2 구현
- LAS
- Extra 모델 아키텍쳐
- Extra 모델 아키텍쳐
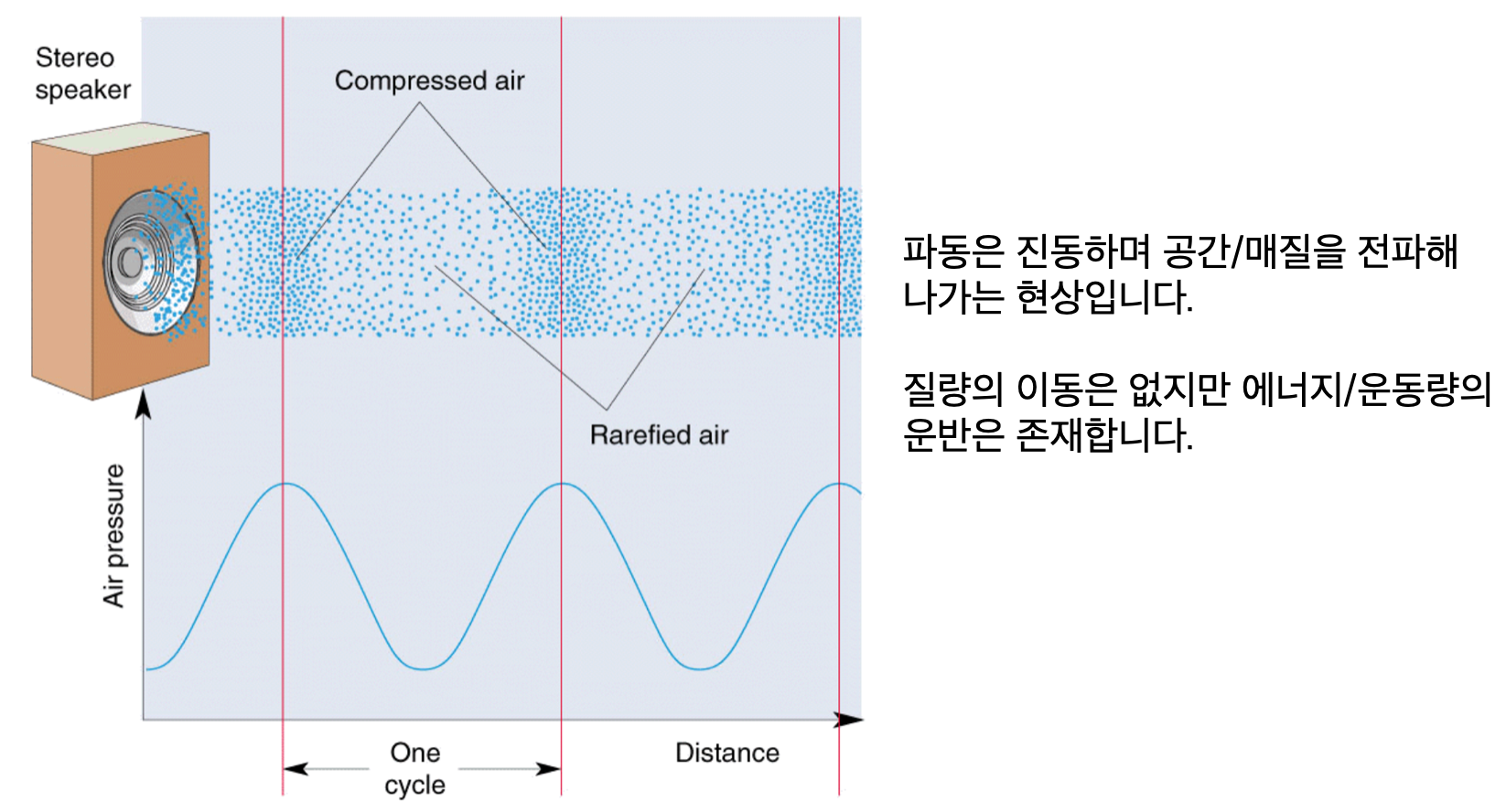
소리란?
진동으로 인한 공기의 압축, 소리는 횡파가 아닌 종파인데요, 어떤 소리마다 종파가 진행하면서 공기가 압축이 되는 부분과 널널하게 퍼져있는 부분이 생기기 마련입니다.
그 형상을 횡파로 분류하면 압축된 부분을 신호가 큰 것으로 보고 그리면 위 사진과 같습니다.
소리에서 얻을 수 있는 물리량들은 다음과 같습니다.
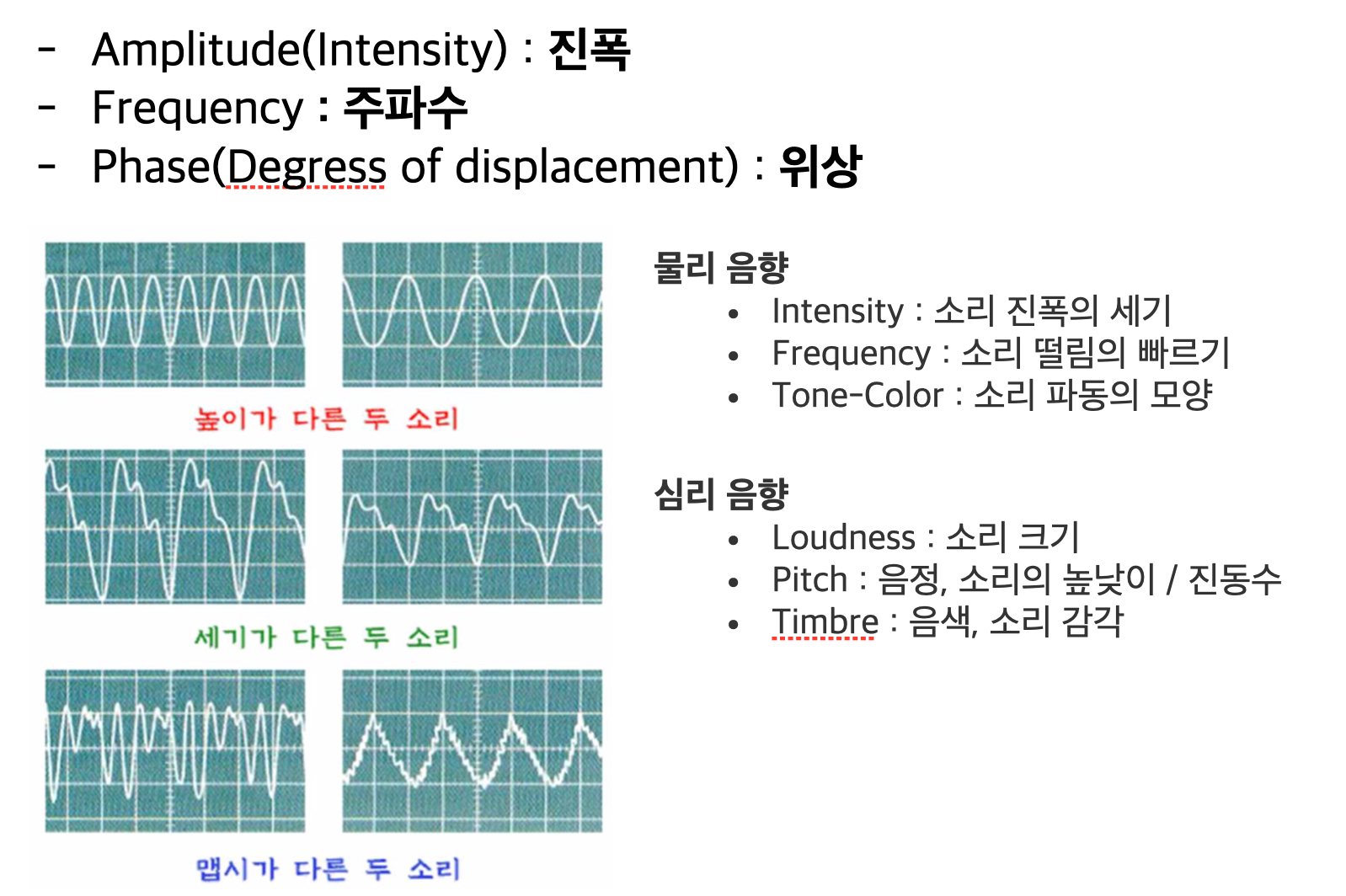
소리가 클수록 진폭이 클 것이며, 파형의 모양에 따라 소리의 생김새가 달라질 것입니다.
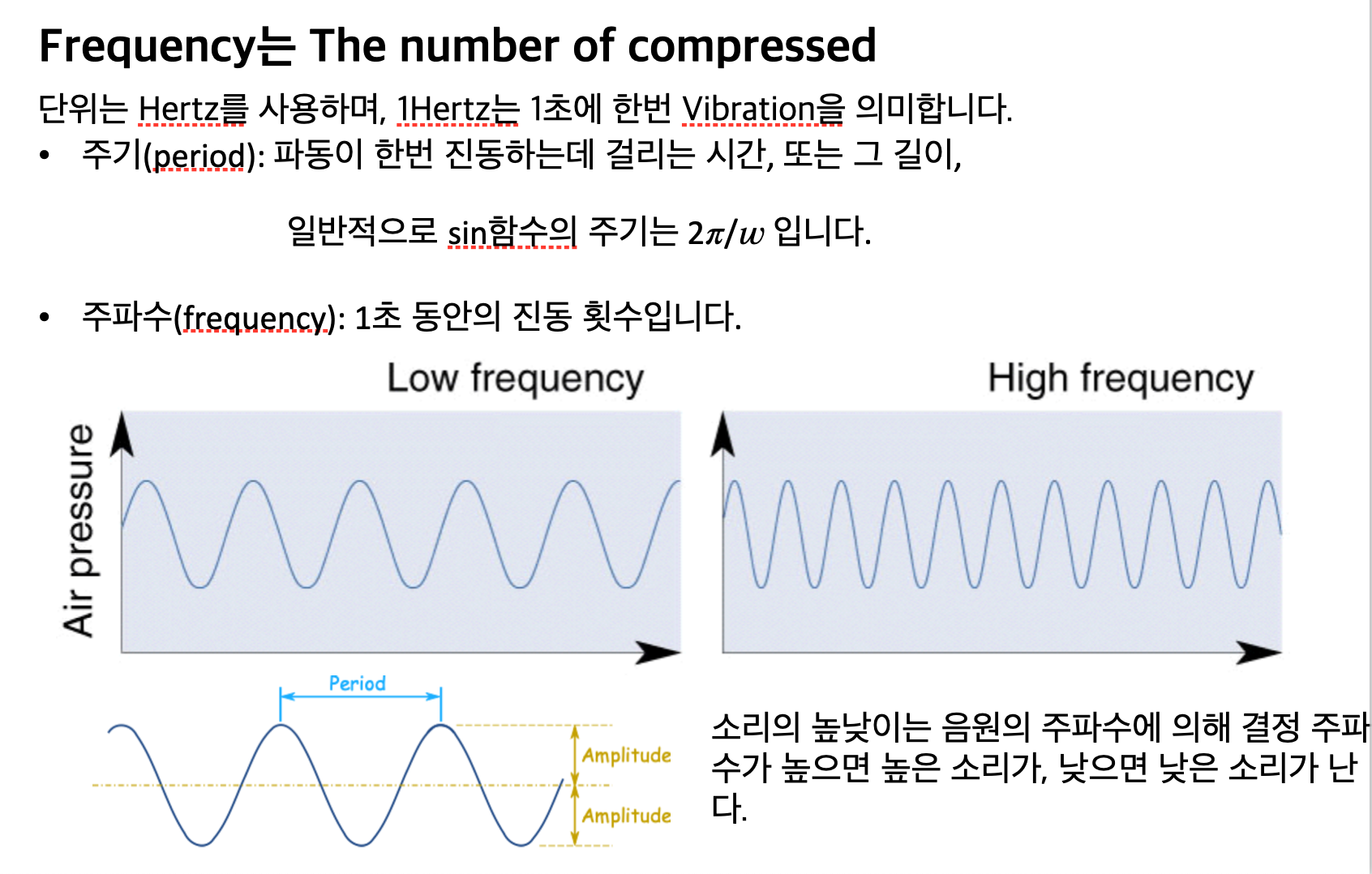
또 진동수가 클수록 고음으로 향하겠죠?
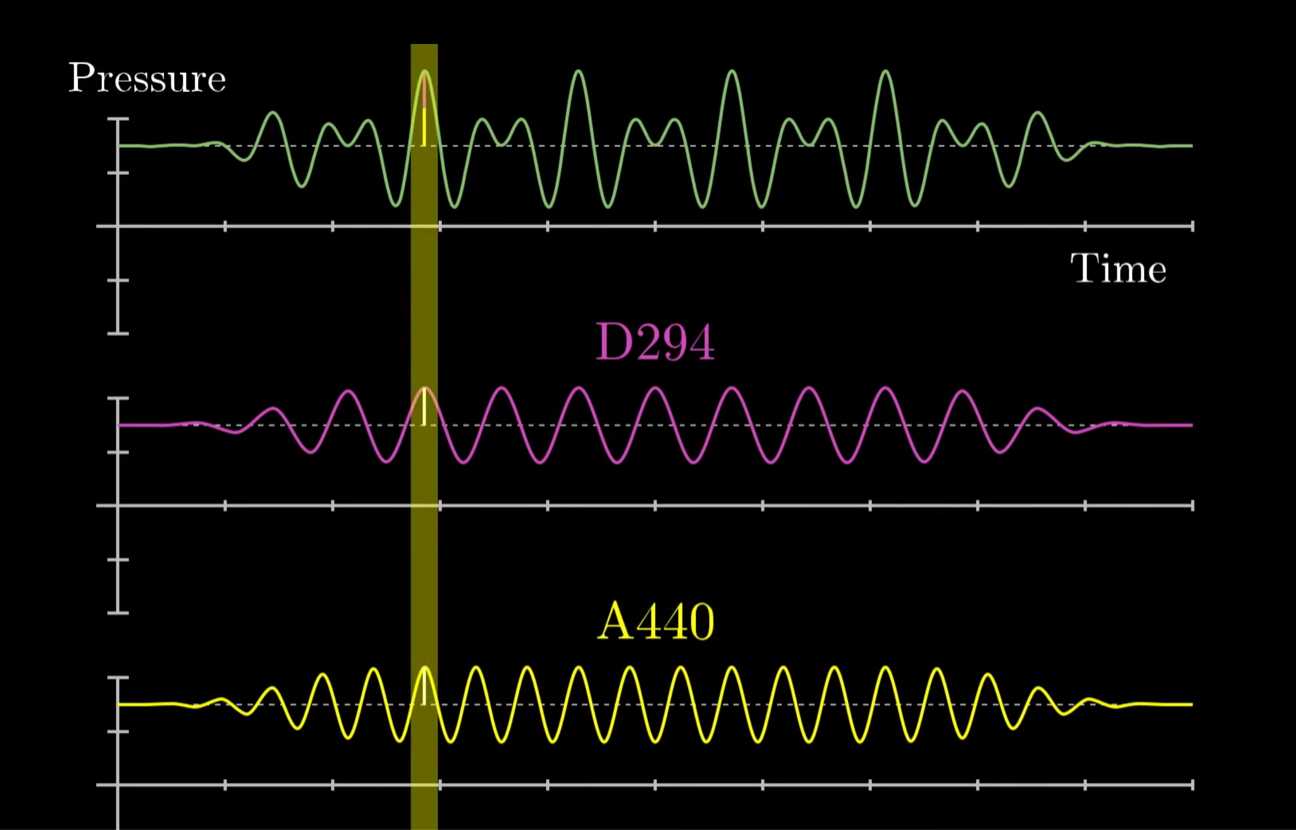
우리가 사용하는 대부분의 소리들은 복합파입니다. 복합파(Complex wave)는 서로 다른 정현파들의 합으로 이루어진 파형을 말합니다.
(정현파란 사인함수 파형을 말합니다.)
Fourier transform(퓨리에 변환)
푸리에 변환(Fourier transform)은 신호처리, 음성, 통신 분야에서 뿐만 아니라 영상처리에서도 매우 중요한 개념으로 다양한 응용을 가지고 있습니다.
영상을 주파수 성분으로 변환하여 다양한 분석 및 처리를 할 수 있고 임의의 필터링 연산을 fft(fast Fourier transform)를 이용하여 고속으로 구현할 수도 있습니다.
퓨리에 변환은 임의의 입력 신호를 다양한 주파수들을 갖는 주기함수들의 합으로 분해해서 표현하는 것입니다. (Sin+Cos)
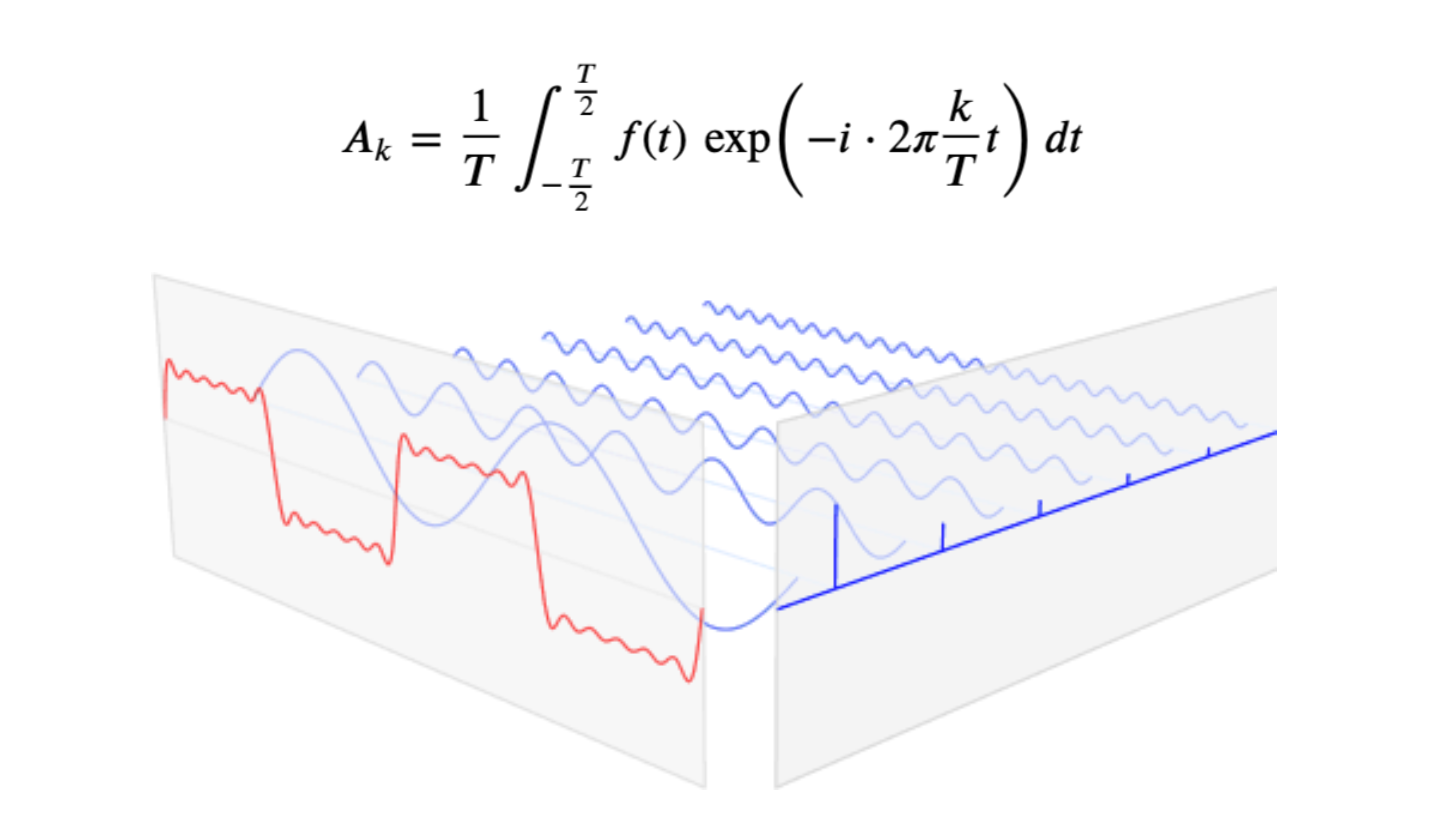
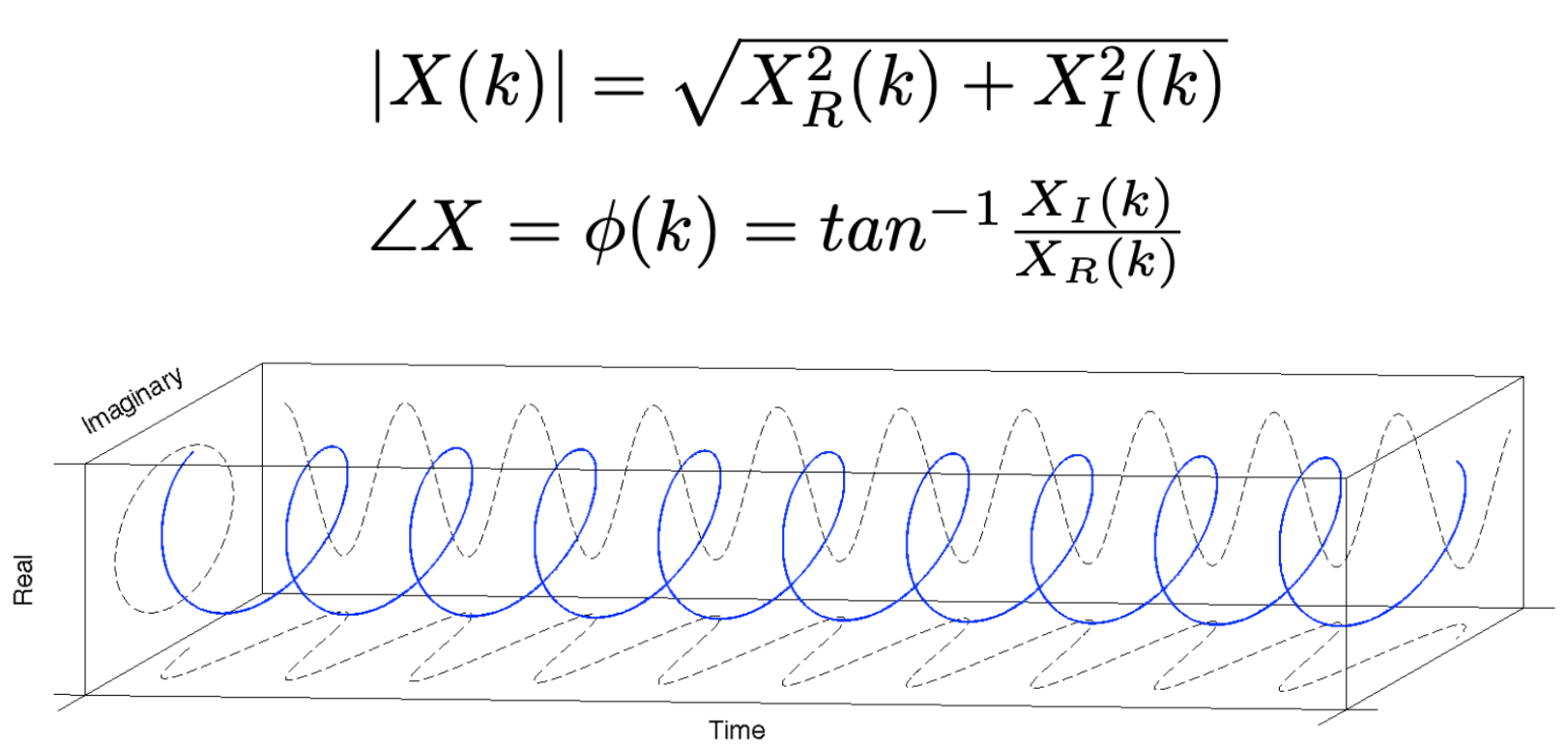
퓨리에 변환이 끝나면, 실수부와 허수부를 가지는 복소수가 얻어지는데, 이러한 복소수의 절대값은 Spectrum Magnitude(주파수 강도)라고 부르며, 복소수가 가지는 Phase를 Phase spectrum(주파수의 위상)이라고 부릅니다.
phase는 복소수의 각도를 말합니다.
Deep Learning Review
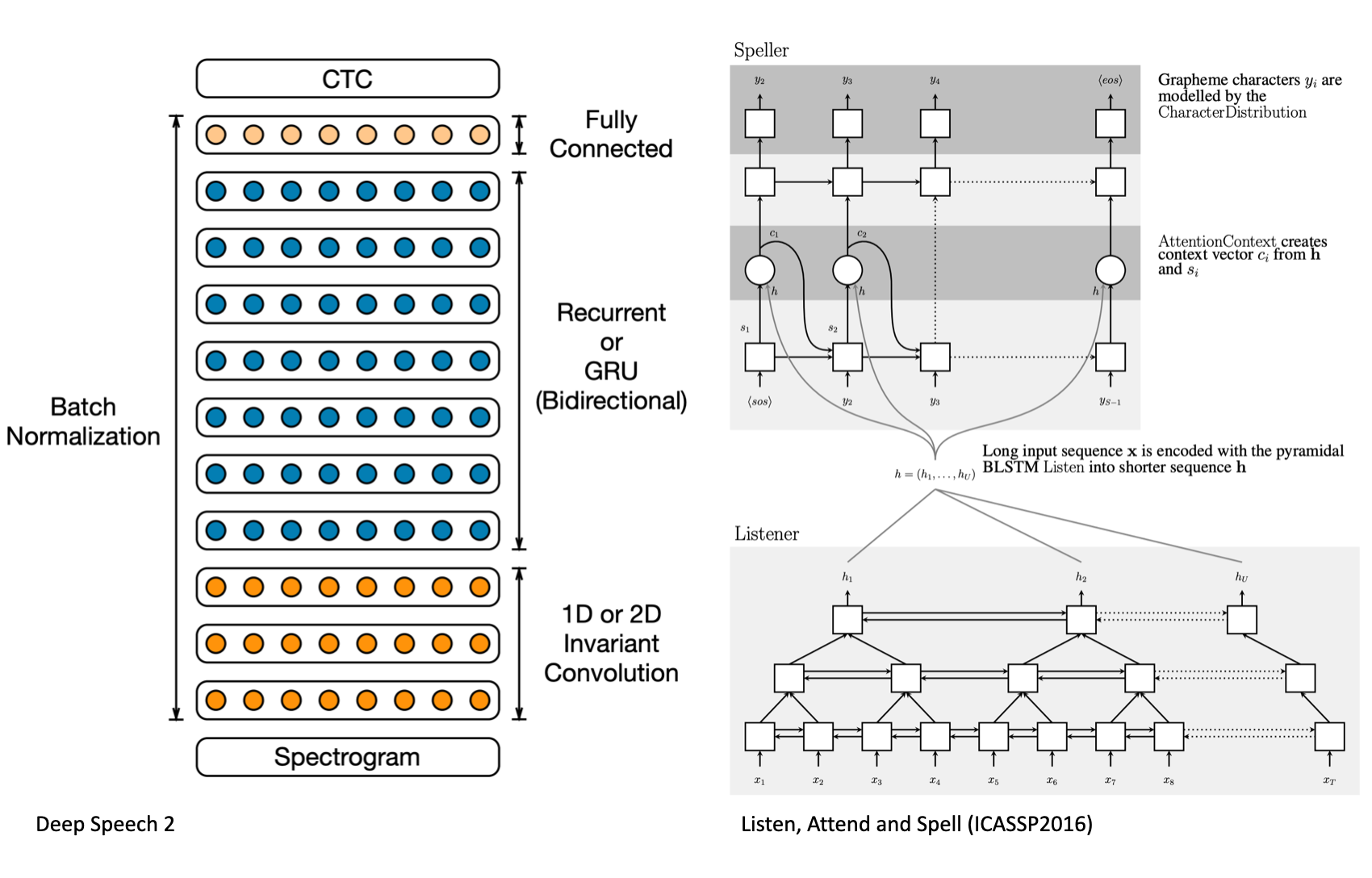
audio classification을 위해서는 딥러닝을 두루두루 잘 알아야 합니다.
일단 지금까지 제가 파악한바로는 퓨리에변환을 거치고 나온 스펙토그램을 1D or 2D Invariant Convolution 과 Recurrent or GRU 과정을 거쳐 FC layer 방식으로 decod….설명을 못하겠네요,,, 공부하겠습니다..
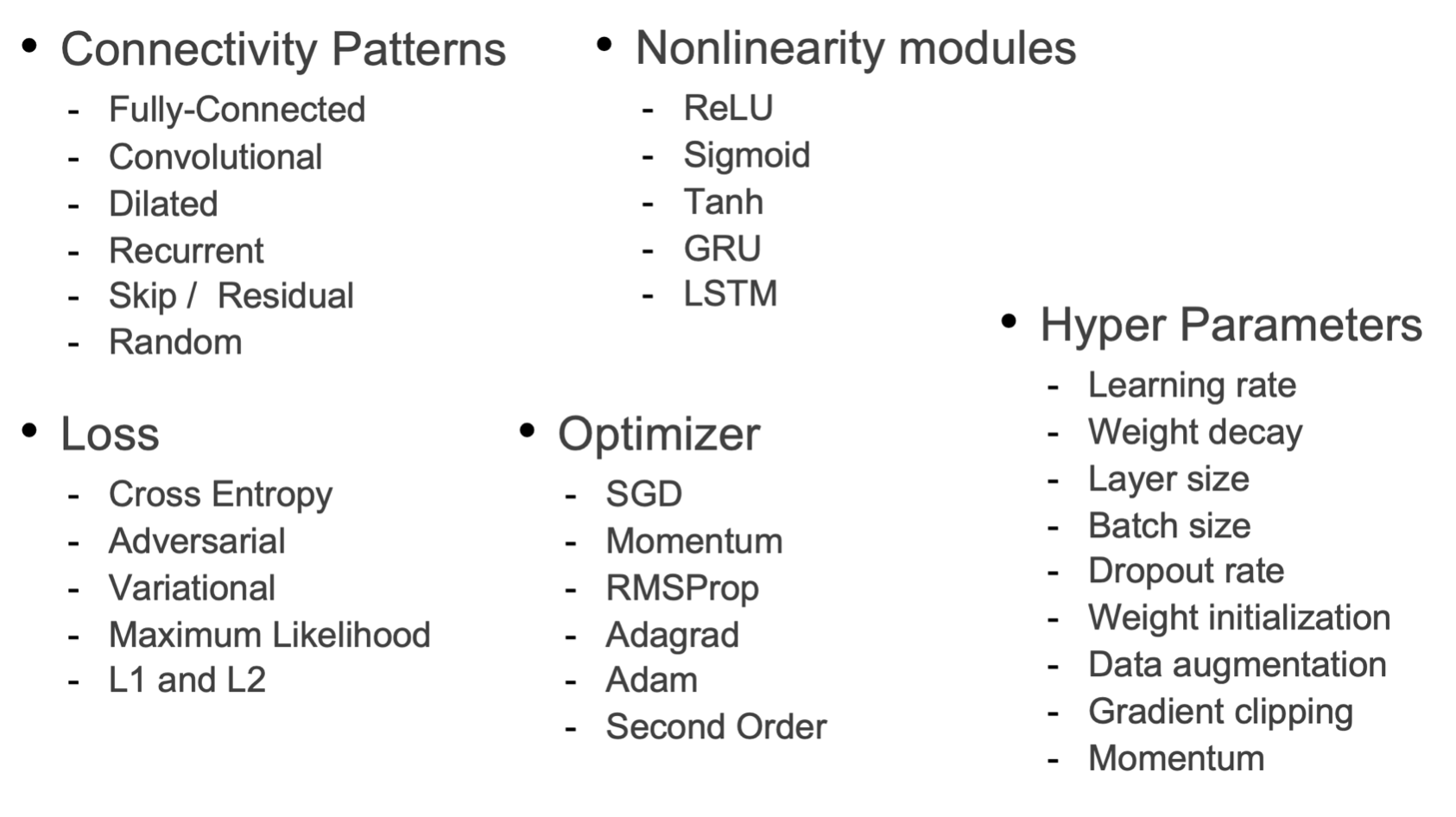
딥러닝 스터디에서 배웠던 것들이 이제 꽤 보이네요~
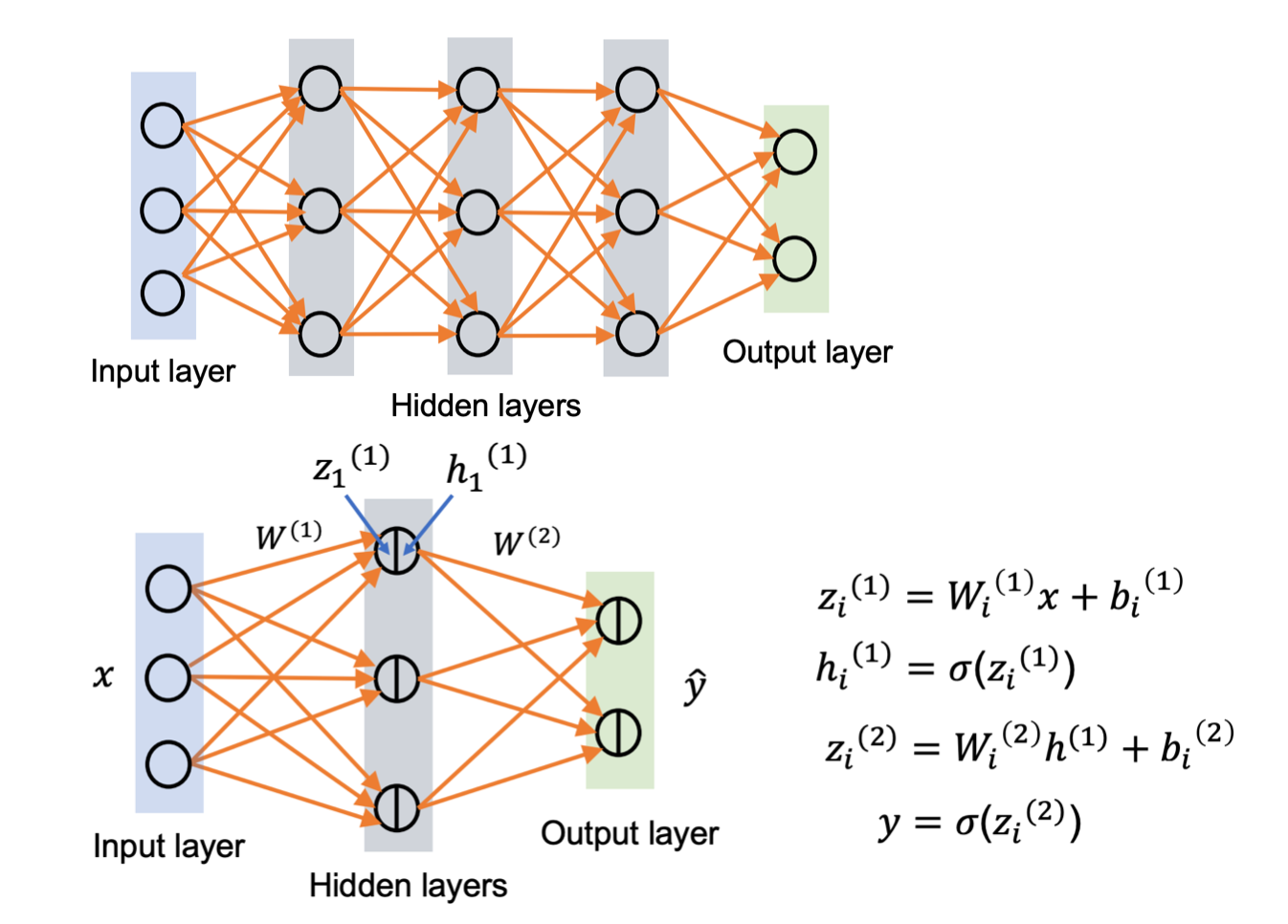
그림과 같은 MLP 구조를 다시 복습해보면, 현재 층과 층사이는 Fully-Connected, 즉 FC layer 형태로 이루어져 있고, 입력층에서 은닉층으로 이동하면서 가중치와 편향이 곱해져 더해집니다.
그 더해진 z값이 다시 활성화함수로 대입이되고 다음 층으로 넘어가게 되는 것을 보실 수 있습니다.
저 시그마에 대한 함수들이 비선형구조의 함수들을 사용하게 됩니다. 물론 선형구조도 사용할 경우가 있겠지만, 우리는 음성을 분류해야하기 때문에 비선형구조의 함수를 사용할 것입니다.
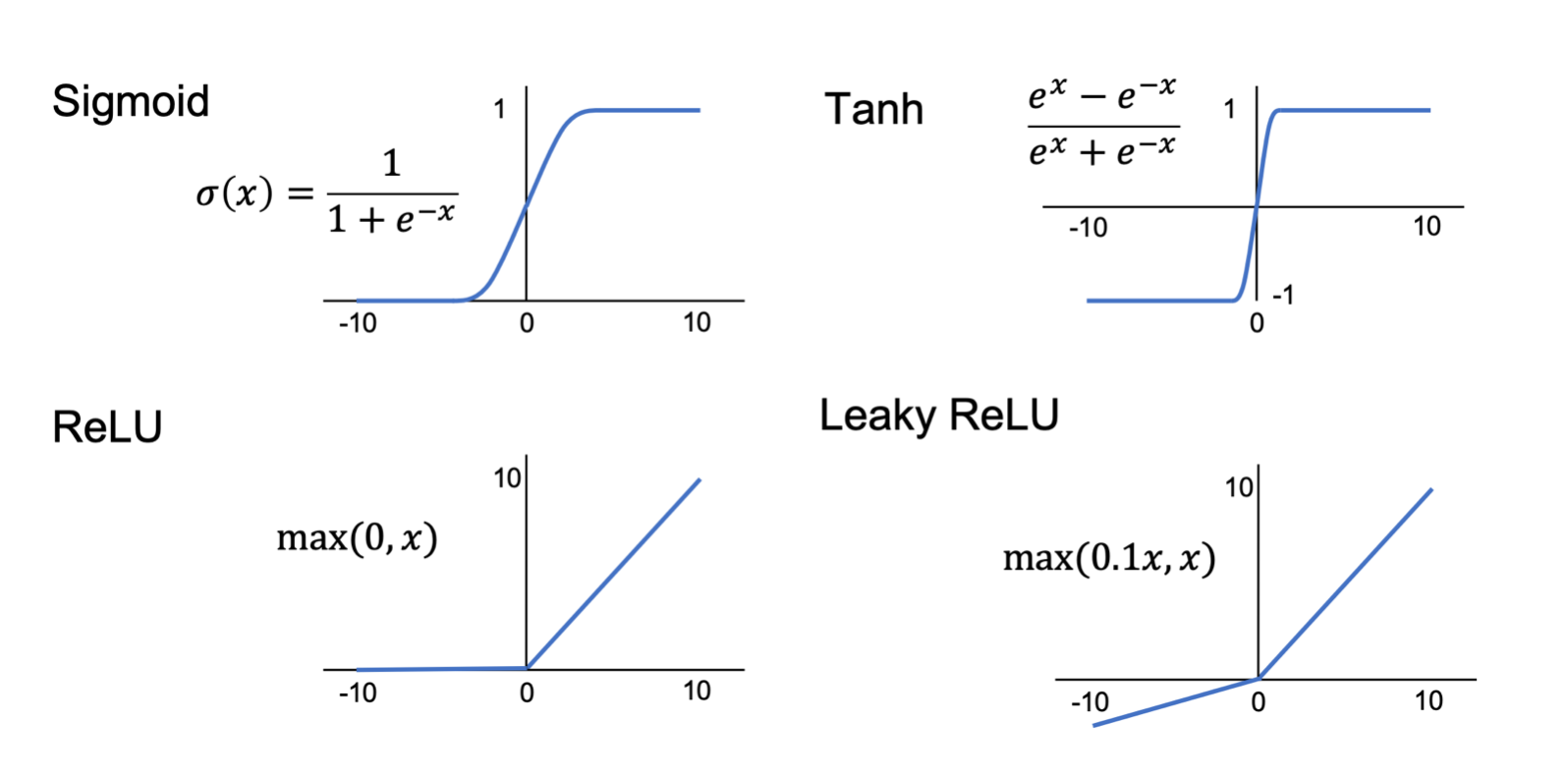
비선형구조 함수들입니다. 그림 외에도 LSTM, GRU 등의 함수들이 있지만 일단은 그렇습니다.
LSTM이 중요하게 쓰인다고 합니다.
CNN(Convolutional Neural Networks)
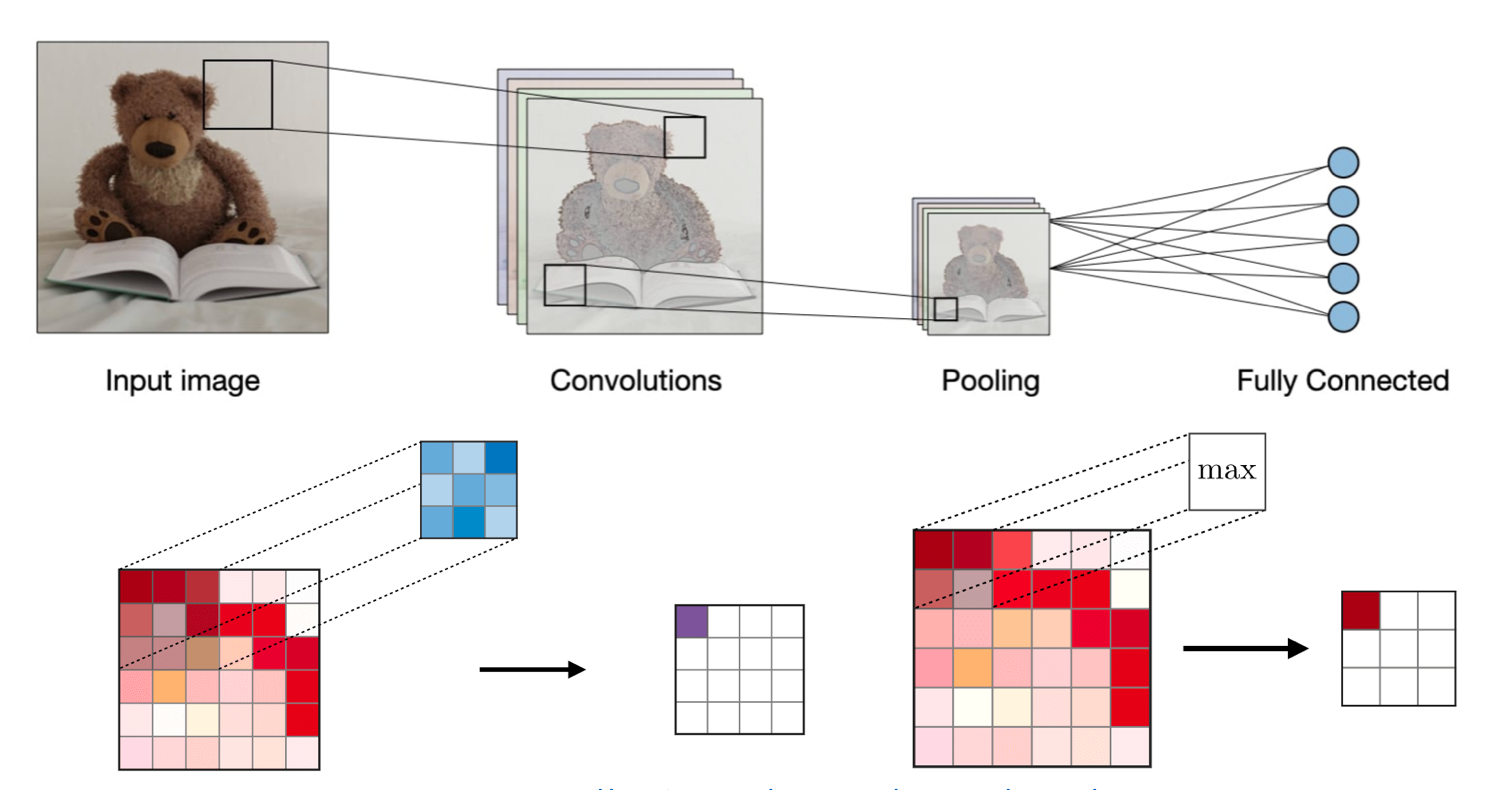
Convolution Layer는 입력을 필터를 사용하여 Convolution 연산을 하게 됩니다. 하이퍼파라미터는 필터크기 F, 보폭 S가 포함됩니다. 결과 출력 O를 feature map 혹은 activation map 이라고 부릅니다.
Pooling Layer는 다운 샘플링 작업으로, 일반적으로 Convolution Layer 이후에 적용되며 spatial invariance을 수행합니다. 특히 Max pool과 Average pool은 각각 최대값과 평균값을 취하는 특수 종류의 풀링입니다.
CNN in Audio
CNN에서 channel 은 없다고 보면 된다고 합니다.
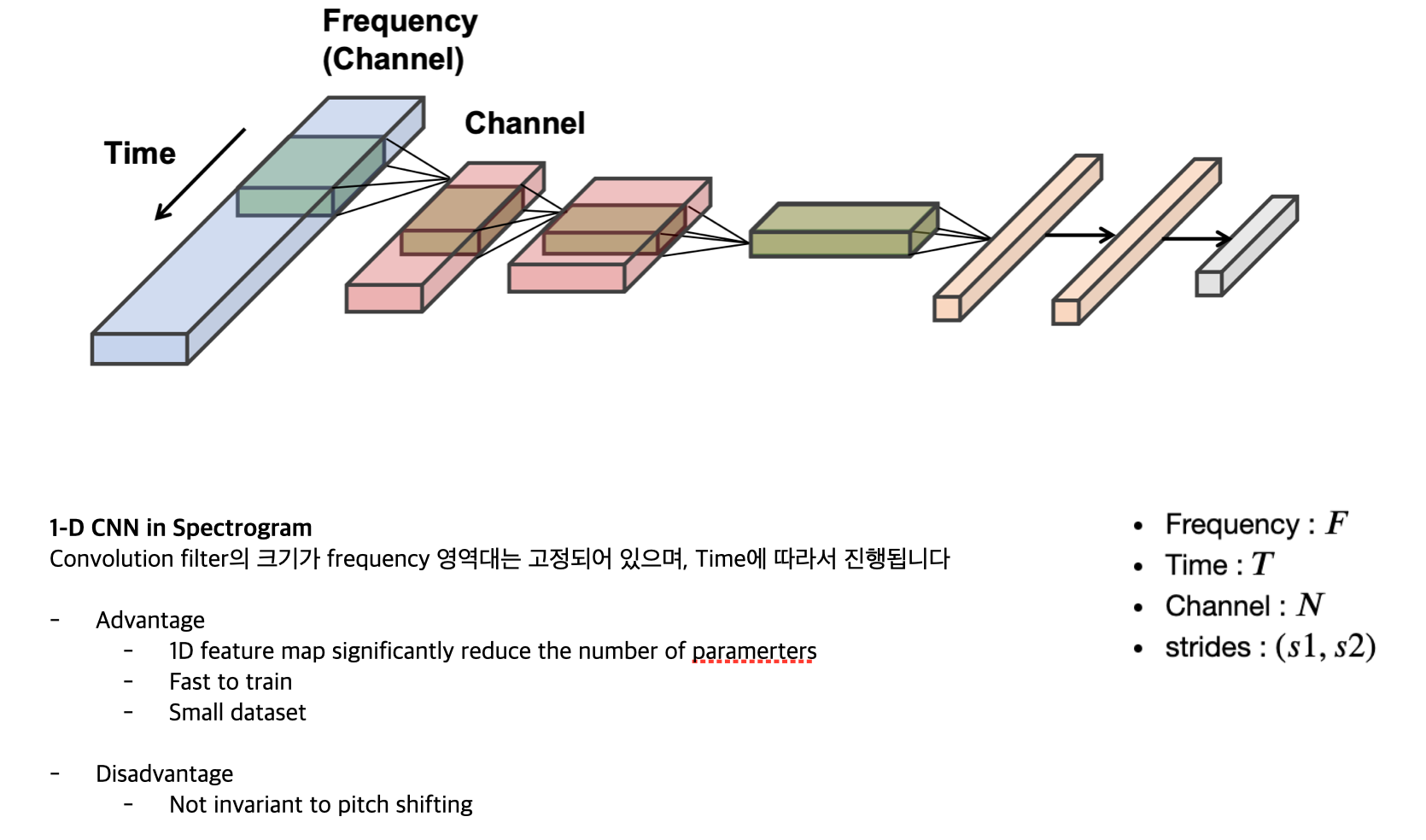
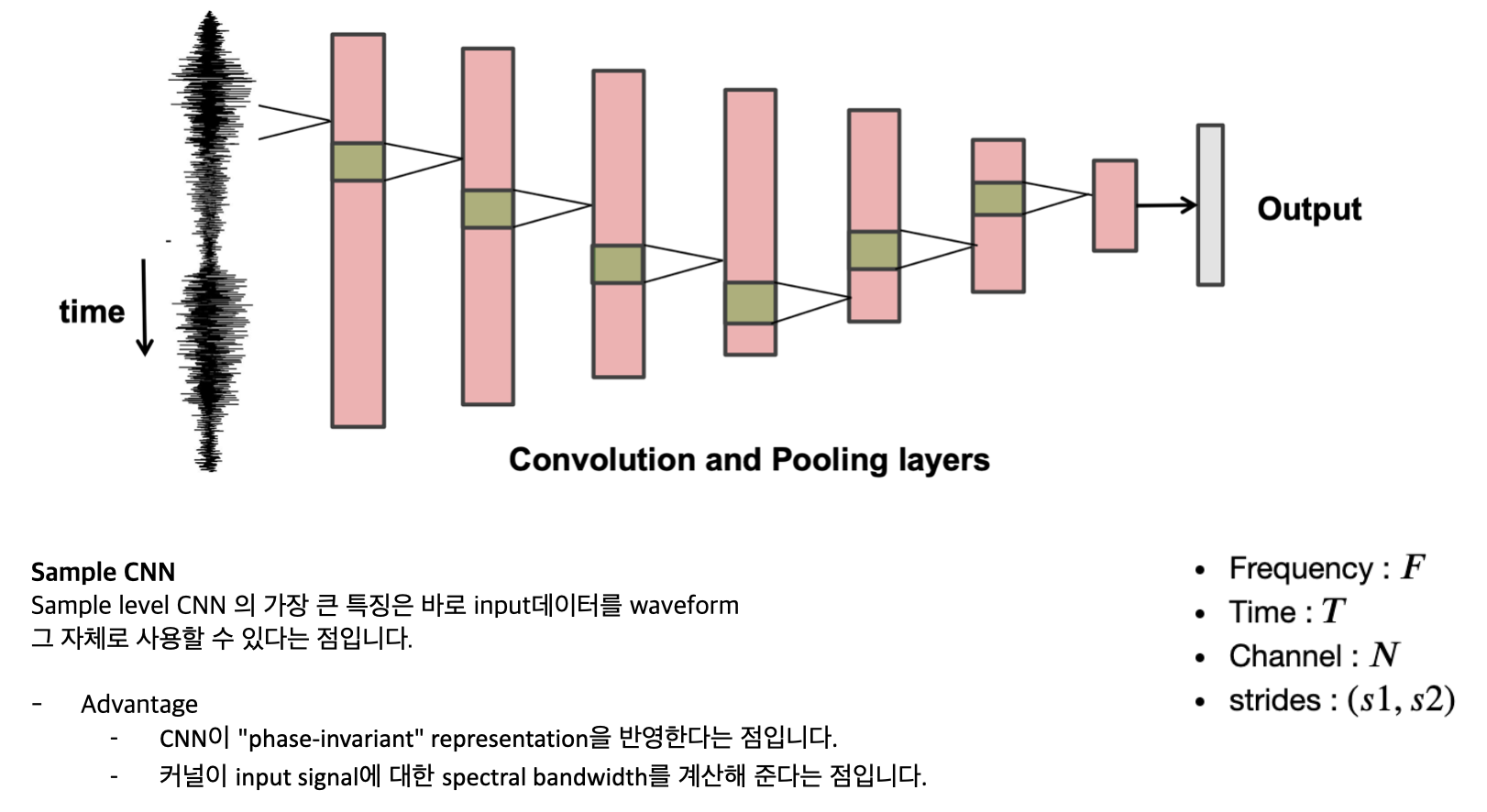
위 그림이 1D CNN입니다.
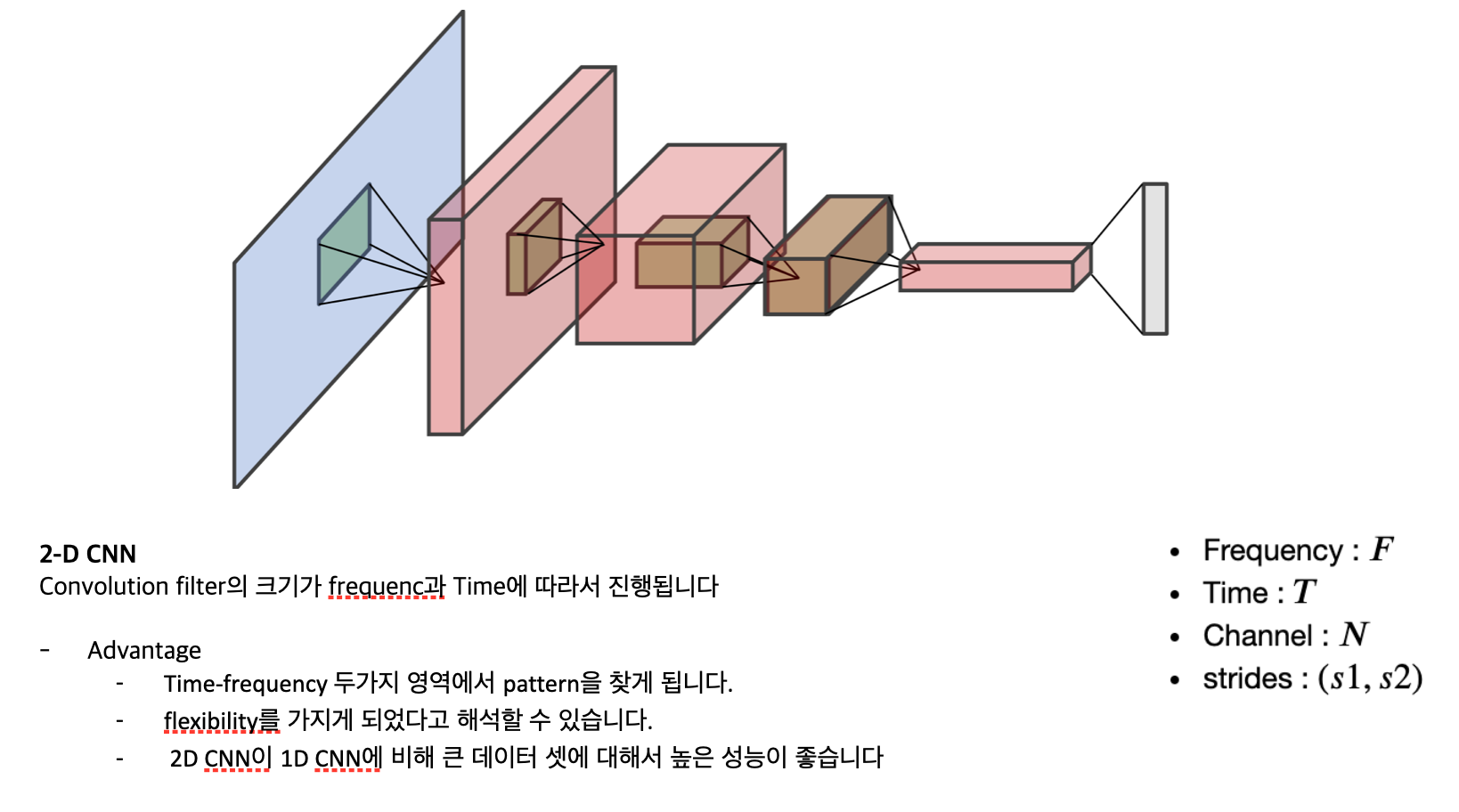
위 그림이 2D CNN입니다.
CNN 공부를 진행해봐야지 좀 알아먹을 것 같습니다 😅
RNN(Recurrent neural network)
RNN은 Hidden State 를 유지하면서 이전 출력을 입력으로 사용할 수 있는 신경망입니다.
- 어떠한 input length든 커버할 수 있습니다.
- 입력 크기에 따라 모델 size가 증가하지 않습니다.
- Historical Information을 잘 활용합니다.
- 시간축에 따른 Weight Sharing이 진행됩니다.
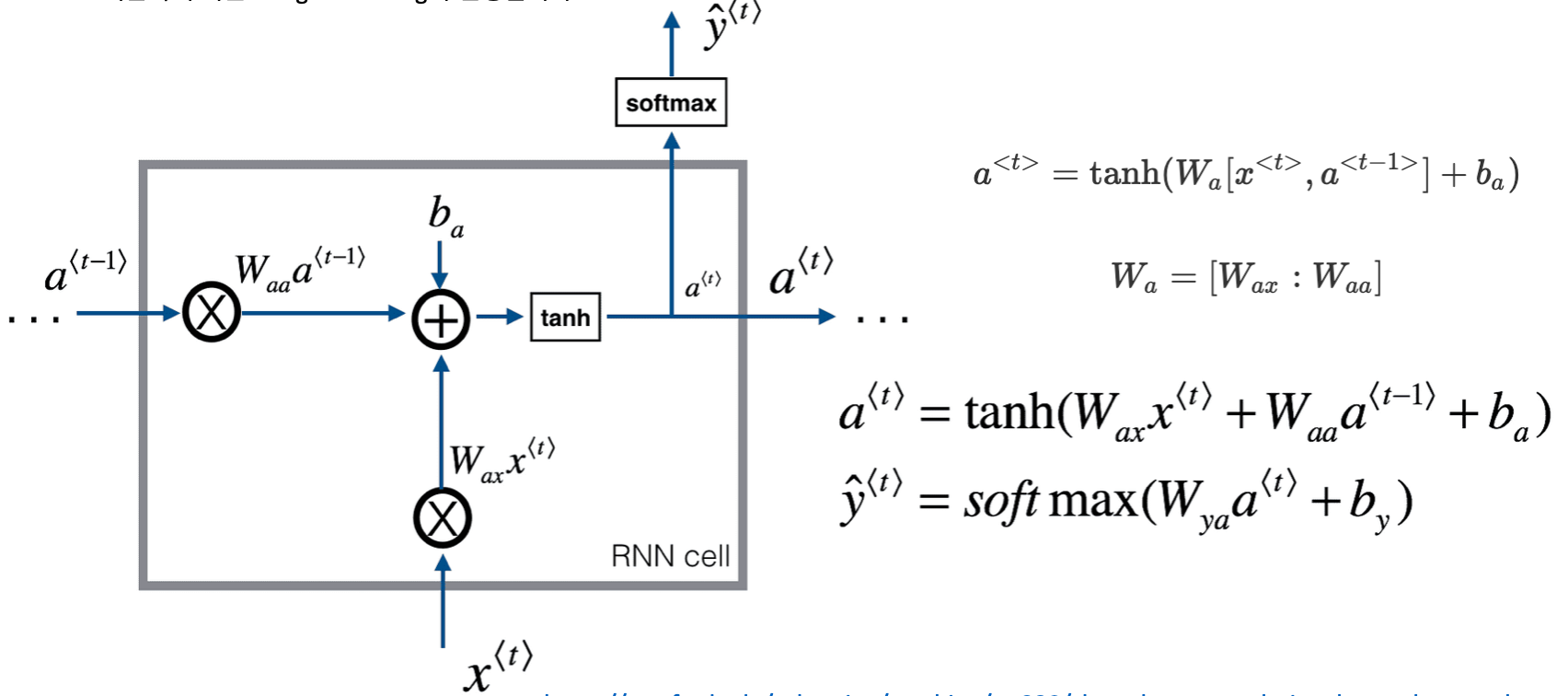
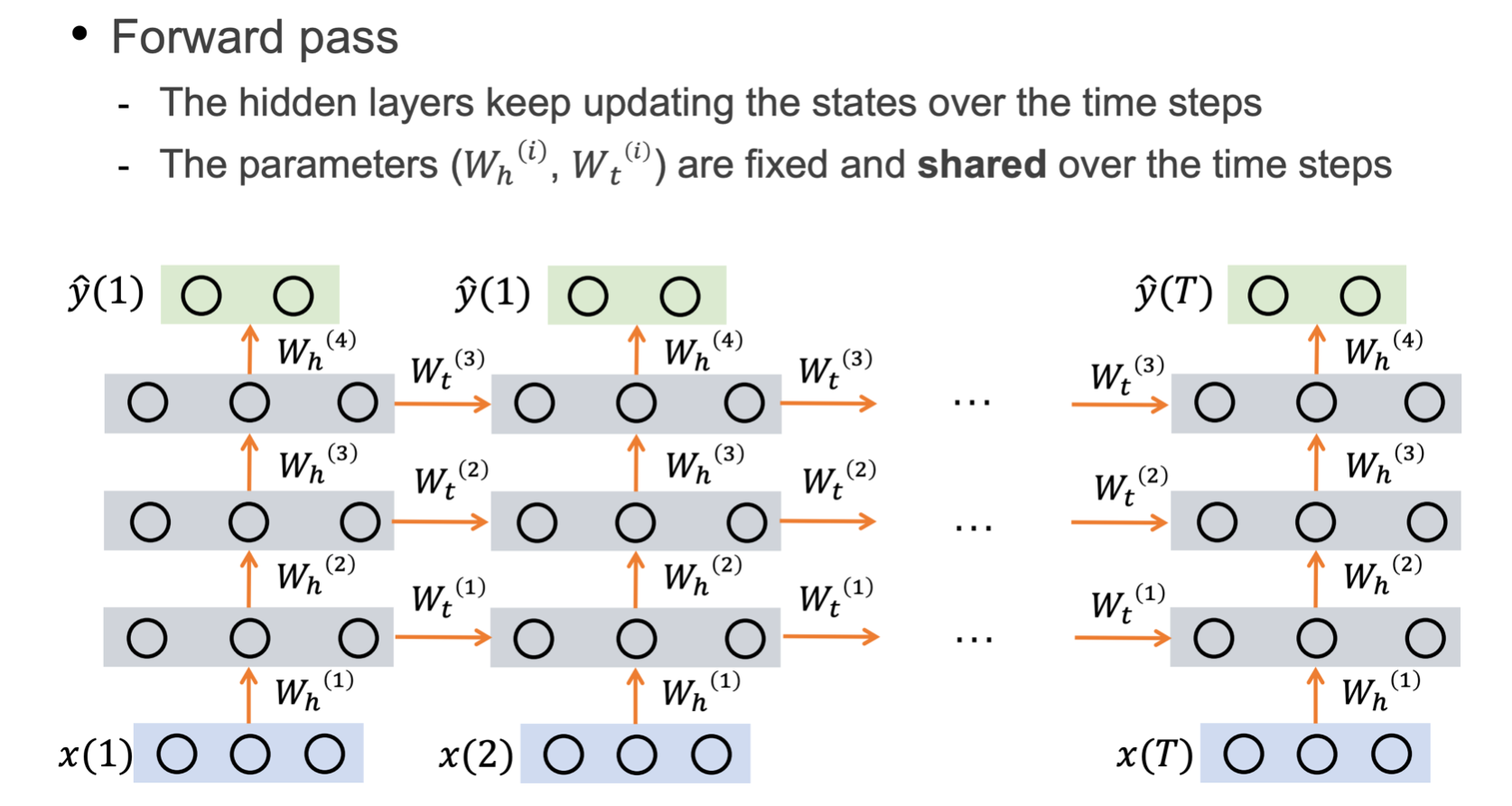
LSTM
GRU (Gated Recurrent Unit) 및 LSTM (Long Short-Term Memory Unit)은 기존 RNN에서 vanishing gradient 를 처리하며 LSTM은 GRU의 일반화된 모델입니다.
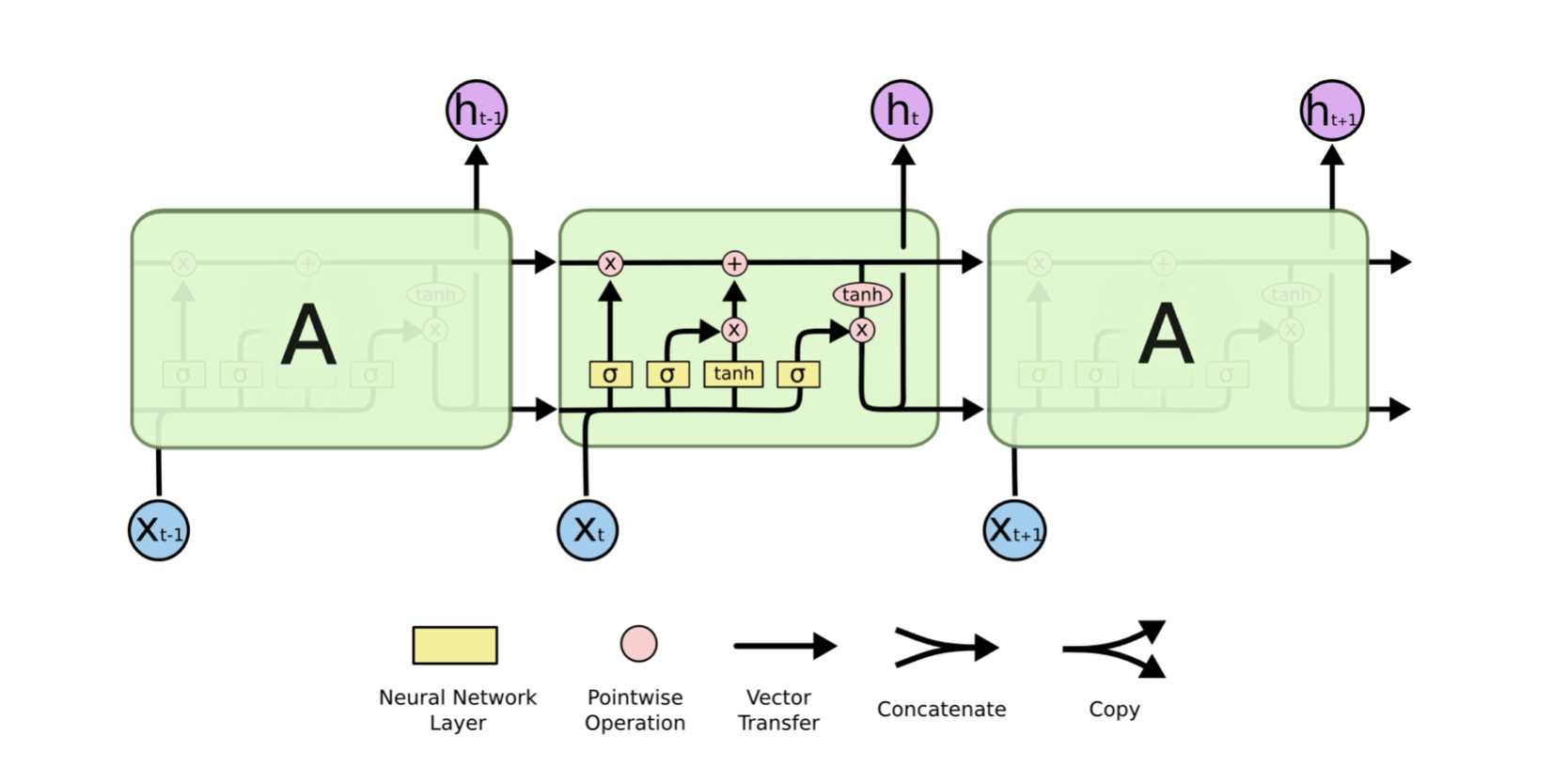
Attention
RNN계열 encoding 방식에서는 계속 마지막 hidden state까지 학습을 하면서 연산을 해야했습니다. 이러한 문제를 해결하는 것이 바로 attention 입니다. Attention은 input source 와 hidden state의 관계를 학습시키는 추가적인 Network를 만들게 됩니다. 이 Attention은 output에 의해서 weight를 학습하게 됩니다.
댓글남기기